


Here's a procedure you can follow to read data from a simple text file into SPSS. The file is named awards.txt. It contains two cases (rows of data) as two lines of text, with the data items in the two lines separated by spaces.
Choose File→Read Text Data.
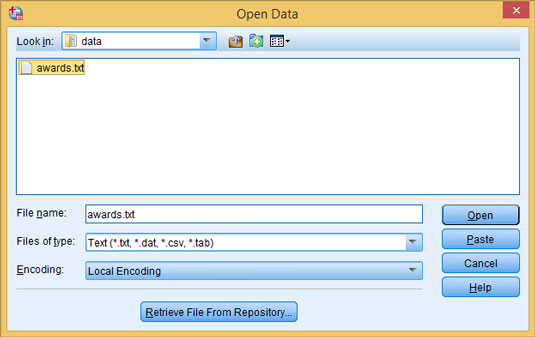
Locate the file you want to read. The Open Data window appears.
Select the awards.txt file, and then click Open.
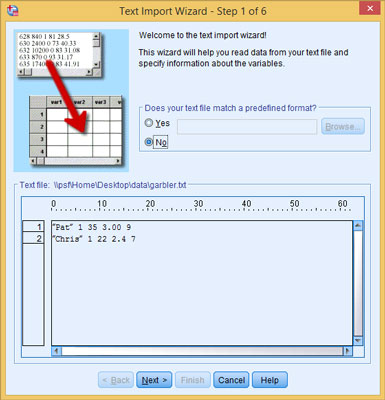
The Text Import Wizard appears, allowing you to load and format your data. Make sure your data looks reasonable.
Examine the input data and click Next.
The screen lets you peek at the contents of the input file so you can verify that you’ve chosen the right file. Also, if your file uses a predefined format (which it doesn’t, in this example), you can select it here and skip some of the later steps. If your data doesn’t show up nicely separated into values the way you want, you may be able to correct it in a later step.
Specify that the data is delimited and the names are not included.
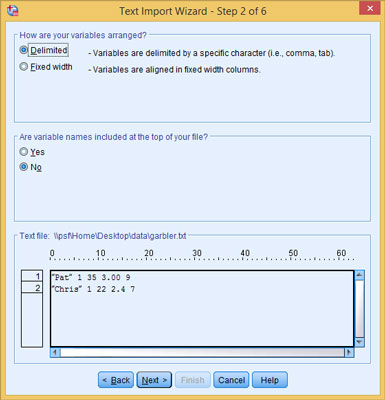
SPSS takes a guess, but you can also specify how your data is organized. It can be divided using spaces, commas, tabs, semicolons, or some combination. Or your data may not be divided — it may be that all the data items are jammed together and each has a fixed width.
Click Next.
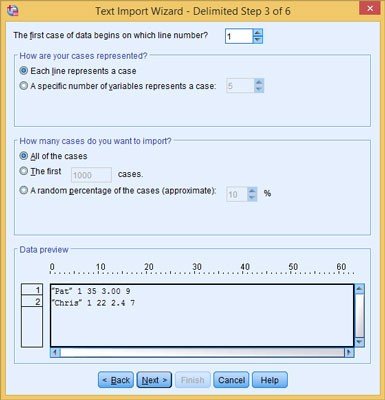
Specify where the data appears in the file.
Specify how SPSS is to interpret the text.
You can tell SPSS something about the file and which data you want to read. Also, you can have one line of text represent one case (one row of data in SPSS), or you can have SPSS count the variables to determine where each row starts.
And you don’t have to read the entire file — you can select a maximum number of lines to read starting at the beginning of the file, or you can select a percentage of the total and have lines of text randomly selected throughout the file. Specifying a limited selection can be useful if you have a large file and would like to test parts of it.
Click Next and specify space as the delimiters and double quotes as text qualifiers.
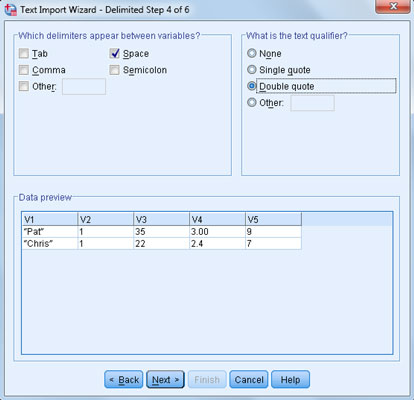
SPSS knows how to use commas, spaces, tabs, and semicolons as delimiting characters. You can even use some other character as a delimiter by selecting Other and then typing the character into the blank. You can also specify whether your text is formatted with quotes (as in our example) and whether you use single or double quotes. Strings must be surrounded in quotes if they contain any of the characters being used as delimiters.
You can specify that a data item is missing in your text file. Simply use two delimiters in a row, without intervening data.
Click Next and change the variable name and data format (optional).
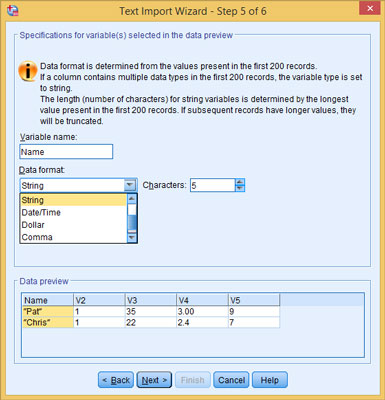
SPSS assigns the variables the names V1, V2, V3, and so on. To change a name, select it in the column heading at the bottom of the window, and then type the new name in the Variable Name field at the top. You can select the format from the Data Format drop-down list, as shown in Figure 5-6.
Click Next. Save the format, grab the syntax, or enable caching.
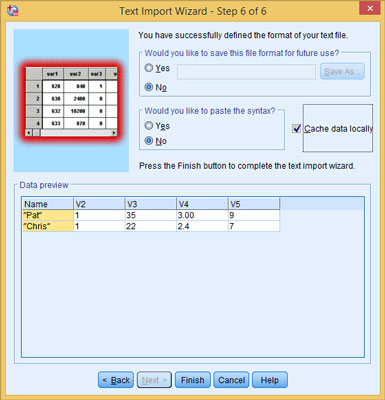
In the Would You Like to Save This File Format for Future Use? Section, click No.
Saving the file format for future use is something you would do if you were loading more files of this same format into SPSS — it reduces the number of questions to answer and the amount of formatting to do next time.
Click the Finish button.
Depending on the type of data conversions and the amount of formatting, SPSS may take a bit of time to finish. But be patient. The Data View tab of the Data Editor window will eventually display your data.
Look at the data.
You’re instructed to enter a filename. You can just call it Awards. The new file will have the .sav extension, which indicates that it’s a standard SPSS file.
The SPSS way of reading data is a lot more flexible than this simple example demonstrates. Another example can help show why. Here, a file named AwardHeader.txt includes the same data, formatted slightly differently:
This time the data in the file is preceded by the variable names listed on the first line, the data is all in one long line, and the data is separated by commas. To read this into SPSS, you start the same way you did before. However, SPSS can’t figure it all out in Step 1 this time. SPSS can’t even tell which is header and which is data.
Correct your data types and formats, if necessary. Then save it all to a file by choosing File→Save As.
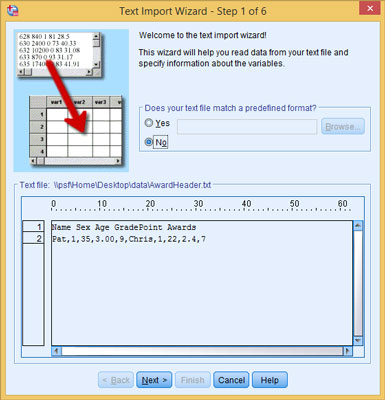
The data remains as a block of text until you explain the parts.
In Step 2 of 6, you select the option that informs SPSS that the variable names appear in the first line of text.
In Step 3 of 6, you specify that the data begins on line 2 of the text file and each case has five data items.
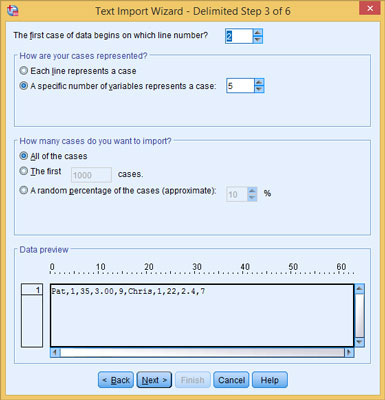
It’s possible for the data to begin several lines down in the input text file, but if variable names are present, they must be on the first line. Also, when you specify variable names, SPSS ignores the beginning and ending of lines, and counts the data values to determine when it has a complete row (case).
Specify delimiters and quote characters.
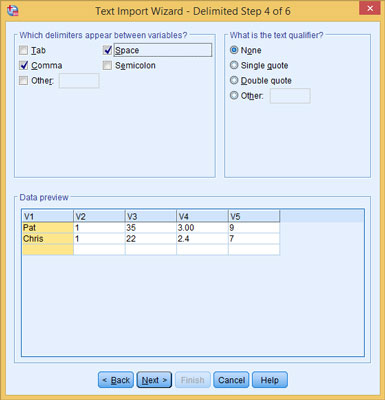
In Step 4 of 6, commas and spaces were chosen as delimiters. (Although no spaces appear in the data in this example, it doesn’t hurt to include a space delimiter if it may occur somewhere in your data.) Also, None was chosen for the characters surrounding string values. In this example, SPSS figured out the spacing on its own and used these settings for its default. Also, by the time you reach Step 4 of 6, SPSS has started organizing the data according to your definitions. It has already read the variable names and included them as column headers.
Change the variable names and specify their types.
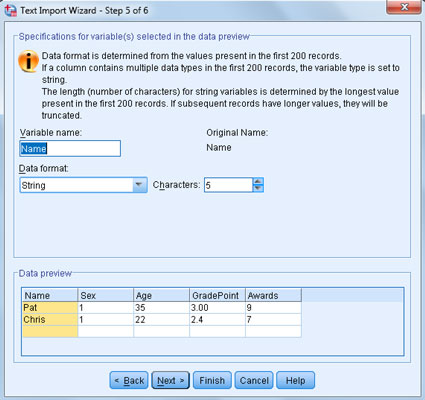
Here again, you see that SPSS has made a guess for the type of each one.
After you complete Step 6 of 6, click the Finish button and wait for the data to load.
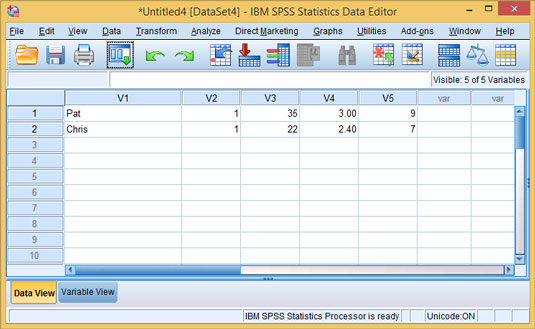
The data as formatted in SPSS.
