


In such case, the problem with a complex mapping is that it has many terms and parameters — and in some extreme cases, your algorithm may have more parameters than your data has examples. Because you must specify all the parameters, the algorithm then starts memorizing everything in the data — not just the signals but also the random noise, the errors, and all the slightly specific characteristics of your sample.
In some cases, it can even just memorize the examples as they are. However, unless you’re working on a problem with a limited number of simple features with few distinct values (basically a toy dataset, that is, a dataset with few examples and features, thus simple to deal with and ideal for examples), you’re highly unlikely to encounter the same example twice, given the enormous number of possible combinations of all the available features in the dataset.
When memorization happens, you may have the illusion that everything is working well because your machine learning algorithm seems to have fitted the in-sample data so well. Instead, problems can quickly become evident when you start having it work with out-of-sample data and you notice that it produces errors in its predictions as well as errors that actually change a lot when you relearn from the same data with a slightly different approach.
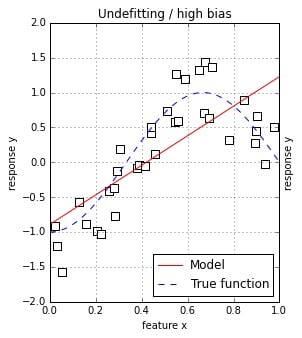
Overfitting occurs when your algorithm has learned too much from your data, up to the point of mapping curve shapes and rules that do not exist. Any slight change in the procedure or in the training data produces erratic predictions.
 Example of a linear model going right and becoming too complex while trying to map a curve function.
Example of a linear model going right and becoming too complex while trying to map a curve function.


