
After each layer processes its data, it outputs the transformed data to the next layer. That next layer processes the data with complete independence from the previous layers. The use of this strategy implies that if you are feeding a video to your neural network, the network will process each image singularly, one after the other, and the result won't change at all even if you shuffled the order of the provided images. When running a network in such a fashion, you won't get any advantage from the order of the information processing.
However, experience also teaches that to understand a process, you sometimes have to observe events in sequence. When you use the experience gained from a previous step to explore a new step, you can reduce the learning curve and lessen the time and effort needed to understand each step.
Recurrent neural networks: Modeling sequences using memory
Some neural architectures don’t allow you to process a sequence of elements simultaneously using a single input. For instance, when you have a series of monthly product sales, you accommodate the sales figures using twelve inputs, one for each month, and let the neural network analyze them at one time. It follows that when you have longer sequences, you need to accommodate them using a larger number of inputs, and your network becomes quite huge because each input should connect with every other input. You end up having a network characterized by a large number of connections (which translates into many weights), too.Recurrent Neural Networks (RNNs) are an alternative to the perceptron and CNNs. They first appeared in the 1980s, and various researchers have worked to improve them until they recently gained popularity thanks to the developments in deep learning and computational power.
The idea behind RNNs is simple, they examine each element of the sequence once and retain memory of it so they can reuse it when examining the next element in the sequence. It’s akin to how the human mind works when reading text: a person reads letter by letter the text but understands words by remembering each letter in the word. In a similar fashion, an RNN can associate a word to a result by remembering the sequence of letters it receives. An extension of this technique makes it possible ask an RNN to determine whether a phrase is positive or negative—a widely used analysis called sentiment analysis. The network connects a positive or negative answer to certain word sequences it has seen in training examples.
You represent an RNN graphically as a neural unit (also known as a cell) that connects an input to an output but also connects to itself. This self-connection represents the concept of recursion, which is a function applied to itself until it achieves a particular output. One of the most commonly used examples of recursion is computing a factorial. The image below shows a specific RNN example using a letter sequence to make the word jazz. The right side of the image below depicts a representation of the RNN unit behavior receiving jazz as an input, but there is actually only the one unit, as shown on the left.
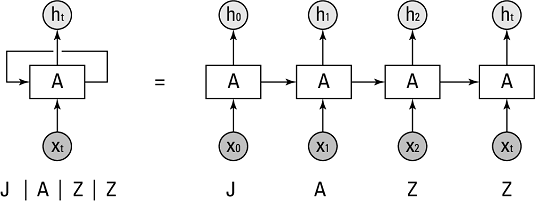 A folded and unfolded RNN cell processing a sequence input.
A folded and unfolded RNN cell processing a sequence input.
This image shows a recursive cell on the left and expands it as an unfolded series of units that receives the single letters of the word jazz on the right. It starts with j, followed by the other letters. As this process occurs, the RNN emits an output and modifies its internal parameters. By modifying its internal parameters, the unit learns from the data it receives and from the memory of the previous data. The sum of this learning is the state of the RNN cell.
When discussing neural networks, you will hear lots of discussion about weights. With RNNs, you also need to know the term state. The weights help process the input into an output in an RNN, but the state contains the traces of the information the RNN has seen so far, so the state affects the functioning of the RNN. The state is a kind of short-term memory that resets after a sequence completes. As an RNN cell gets pieces of a sequence, it does the following:
- Processes them, changing the state with each input.
- Emits an output.
- After seeing the last output, the RNN learns the best weights for mapping the input into the correct output using backpropagation.
Recurrent neural networks: Recognizing and translating speech
The capability to recognize and translate between languages becomes more important each day as economies everywhere become increasingly globalized. Language translation is an area in which AI has a definite advantage over humans — so much so that articles from Digitalist Magazine and Forbes are beginning to question how long the human translator will remain viable.Of course, you must make the translation process viable using deep learning. From a neural architecture perspective, you have a couple of choices:
- Keep all the outputs provided by the RNN cell
- Keep the last RNN cell output
You can also stack RNNs horizontally in the same layer. Allowing multiple RNNs to learn from a sequence can help it get more from the data. Using multiple RNNs is similar to CNNs, in which each single layer uses depths of convolutions to learn details and patterns from the image. In the multiple RNNs case, a layer can grasp different nuances of the sequence they are examining.
Designing grids of RNNs, both horizontally and vertically, improves predictive performances. However, deciding how to use the output determines what a deep learning architecture powered by RNNs can achieve. The key is the number of elements used as inputs and the sequence length expected as output. As the deep learning network synchronizes the RNN outputs, you get your desired outcome.
You have a few possibilities when using multiple RNNs, as depicted in the image below:
- One to one: When you have one input and expect one output. They take one case, made up of a certain number of informative variables, and provide an estimate, such as a number or probability.
- One to many: Here you have one input and you expect a sequence of outputs as a result. Automatic captioning neural networks use this approach: You input a single image and produce a phrase describing image content.
- Many to one: The classic example for RNNs. For example, you input a textual sequence and expect a single result as output. You see this approach used for producing a sentiment analysis estimate or another classification of the text.
- Many to many: You provide a sequence as input and expect a resulting sequence as output. This is the core architecture for many of the most impressive deep learning–powered AI applications. This approach is used for machine translation (such as a network that can automatically translate a phrase from English to German), chatbots (a neural network that can answer your questions and argue with you), and sequence labeling (classifying each of the images in a video).
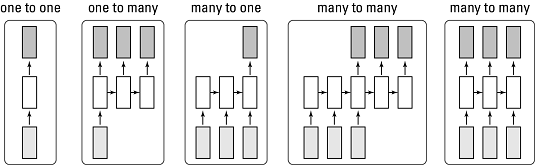 Different RNNs input/output configurations.
Different RNNs input/output configurations.
Machine translation is the capability of a machine to translate, correctly and meaningfully, one human language into another one. This capability is something that scientists have striven to achieve for long time, especially for military purposes. You can read the fascinating story of all the attempts to perform machine translation by U.S. and Russian scientists in the article by Vasily Zubarev. The real breakthrough happened only after Google launched its Google Neural Machine Translation (GNMT), which you can read more about on the Google AI blog. GNMT relies on a series of RNNs (using the many-to-many paradigm) to read the word sequence in the language you want to translate from (called the encoder layer) and return the results to another RNN layer (the decoder layer) that transforms it into translated output.
Neural machine translation needs two layers because the grammar and syntax of one language can be different from another. A single RNN can’t grasp two language systems at the same time, so the encoder-decoder couple is needed to handle the two languages. The system isn’t perfect, but it’s an incredible leap forward from the previous solutions described in Vasily Zubarev’s article, greatly reducing errors in word order, lexical mistakes (the chosen translation word), and grammar (how words are used).
Moreover, performance depends on the training set, the differences between the languages involved, and their specific characteristics. For instance, because of how sentence structure is built in Japanese, the Japanese government is now investing in a real-time voice translator to help during the Tokyo Olympic Games in 2020 and to boost tourism by developing an advanced neural network solution.
RNNs are the reason your voice assistant can answer you or your automatic translator can give you a foreign language translation. Because an RNN is simply a recurring operation of multiplication and summation, deep learning networks can’t really understand any meaning; they simply process words and phrases based on what they learned during training.
Recurrent neural networks: Placing the correct caption on pictures
Another possible application of RNNs using the many-to-many approach is caption generation, which involves providing an image to a neural network and receiving a text description that explains what’s happening in the image. In contrast to chatbots and machine translators, whose output is consumed by humans, caption generation works with robotics. It does more than simply generate image or video descriptions.Caption generation can help people with impaired vision perceive their environment using devices like the Horus wearable or build a bridge between images and knowledge bases (which are text based) for robots — allowing them to understand their surroundings better. You start from specially devised datasets such as the Pascal Sentence Dataset; the Flickr 30K, which consists of Flickr images annotated by crowd sourcing; or the MS Coco dataset. In all these datasets, each image includes one or more phrases explaining the image content. For example, in the MS Coco dataset sample number 5947, you see four flying airplanes that you could correctly caption as:
- Four airplanes in the sky overhead on an overcast day
- Four single-engine planes in the air on a cloudy day
- A group of four planes flying in formation
- A group of airplanes flying through the sky
- A fleet of planes flying through the sky
Google has since open sourced the NIC and offered it as part of the TensorFlow framework. As a neural network, it consists of a pretrained CNN (such as Google LeNet, the 2014 winner of the ImageNet competition) that processes images similarly to transfer learning.
An image is turned into a sequence of values representing the high-level image features detected by the CNN. During training, the embedded image passes to a layer of RNNs that memorize the image characteristics in their internal state. The CNN compares the results produced by the RNNs to all the possible descriptions provided for the training image and an error is computed. The error then backpropagates to the RNN’s part of the network to adjust the RNN’s weights and help it learn how to caption images correctly. After repeating this process many times using different images, the network is ready to see new images and provide its description of these new images.
Recurrent neural networks provide opportunities for more advanced innovation and could help to automate some necessary tasks.