
- Kinds of fields (features or attributes)
- Number of fields
- Number of records (cases)
- Complexity of data
- Task categories (such as classification)
- Missing values
- Data orientation (such as biology)
- Popularity
Given the mandates of the General Data Protection Regulation (GDPR), you also need to exercise care in choosing any dataset that could potentially contain any individually identifiable information. Some people didn’t prepare datasets correctly in the past, and these datasets don’t quite meet the requirements.
Fortunately, you have access to resources that can help you determine whether a dataset is acceptable, such as the dataset found on IBM.Of course, knowing what a standard dataset is and why you would use it are two different questions. Many developers want to test using their own custom data, which is prudent, but using a standard dataset does provide specific benefits, as listed here:
- Using common data for performance testing
- Reducing the risk of hidden data errors causing application crashes
- Comparing results with other developers
- Creating a baseline test for custom data testing later
- Verifying the adequacy of error-trapping code used for issues such as missing data
- Ensuring that graphs and plots appear as they should
- Saving time creating a test dataset
- Devising mock-ups for demo purposes that don’t compromise sensitive custom data
A standardized common dataset is just a starting point, however. At some point, you need to verify that your own custom data works, but after verifying that the standard dataset works, you can do so with more confidence in the reliability of your application code. Perhaps the best reason to use one of these datasets is to reduce the time needed to locate and fix errors of various sorts — errors that might otherwise prove time consuming because you couldn’t be sure of the data that you’re using.
Finding the Right Dataset to meet your functional programming goals
Locating the right dataset for testing purposes is essential in functional programming. Fortunately, you don’t have to look very hard because some online sites provide you with everything needed to make a good decision.Locating general dataset information
Datasets appear in a number of places online, and you can use many of them for general needs. An example of these sorts of datasets appears on the UCI Machine Learning Repository. As the table shows, the site categorizes the individual datasets so that you can find the dataset you need. More important, the table helps you understand the kinds of tasks that people normally employ the dataset to perform.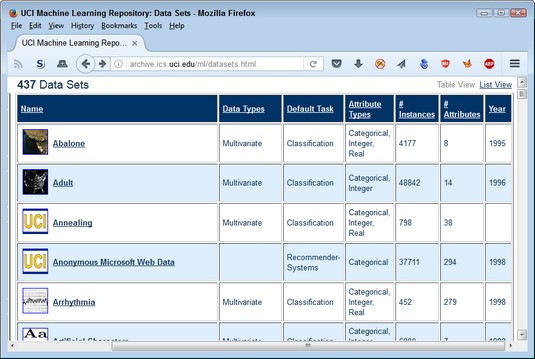 Standardized, common, datasets are categorized in specific ways.
Standardized, common, datasets are categorized in specific ways.
If you want to know more about a particular dataset, you click its link and go to a page like the one you see below. You can determine whether a dataset will help you test certain application features, such as searching for and repairing missing values. The Number of web Hits field tells you how popular the dataset is, which can affect your ability to find others who have used the dataset for testing purposes. All this information is helpful in ensuring that you get the right dataset for a particular need; the goals include error detection, performance testing, and comparison with other applications of the same type.
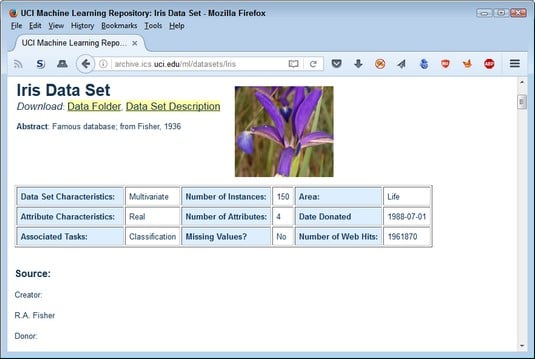 Dataset details are important because they help you find the right dataset to meet your functional programming goals.
Dataset details are important because they help you find the right dataset to meet your functional programming goals.
Even if your language provides easy access to these datasets, getting onto a site such as UCI Machine Learning Repository can help you understand which of these datasets will work best. In many cases, a language will provide access to the dataset and a brief description of dataset content — not a complete description of the sort you find on this site.
Using library-specific datasets
Depending on your programming language, you likely need to use a library to work with datasets in any meaningful way. One such library for Python is Scikit-learn. This is one of the more popular libraries because it contains such an extensive set of features and also provides the means for loading both internal and external datasets. You can obtain various kinds of datasets using Scikit-learn as follows:- Toy datasets: Provides smaller datasets that you can use to test theories and basic coding.
- Image datasets: Includes datasets containing basic picture information that you can use for various kinds of graphic analysis.
- Generators: Defines randomly generated data based on the specifications you provide and the generator used. You can find generators for
- Classification and clustering
- Regression
- Manifold learning
- Decomposition
- Support Vector Machine (SVM) datasets: Provides access to both the svmlight and libsvm implementations, which include datasets that enable you to perform sparse dataset tasks.
- External load: Obtains datasets from external sources. Python provides access to a huge number of datasets, each of which is useful for a particular kind of analysis or comparison. When accessing an external dataset, you may have to rely on additional libraries:
pandas.io: Provides access to common data formats that include CSV, Excel, JSON, and SQL.scipy.io: Obtains information from binary formats popular with the scientific community, including.matand.arfffiles.numpy/routines.io: Loads columnar data into NumPy arrays.skimage.io: Loads images and videos into NumPy arrays.scipy.io.wavfile.read: Reads .wav file data into NumPy arrays.
- Other: Includes standard datasets that provide enough information for specific kinds of testing in a real-world manner. These datasets include (but are not limited to) Olivetti Faces and 20 Newsgroups Text.
How to load a dataset for functional programming
The fact that Python provides access to such a large variety of datasets might make you think that a common mechanism exists for loading them. Actually, you need a variety of techniques to load even common datasets. As the datasets become more esoteric, you need additional libraries and other techniques to get the job done. The following information doesn’t give you an exhaustive view of dataset loading in Python, but you do get a good overview of the process for commonly used datasets so that you can use these datasets within the functional programming environment.Working with toy datasets
As previously mentioned, a toy dataset is one that contains a small amount of common data that you can use to test basic assumptions, functions, algorithms, and simple code. The toy datasets reside directly in Scikit-learn, so you don’t have to do anything special except call a function to use them. The following list provides a quick overview of the function used to import each of the toy datasets into your Python code:load_boston(): Regression analysis with the Boston house-prices datasetload_iris(): Classification with the iris datasetload_diabetes(): Regression with the diabetes datasetload_digits([n_class]): Classification with the digits datasetload_linnerud(): Multivariate regression using the linnerud datasetload_wine(): Classification with the wine datasetload_breast_cancer(): Classification with the Wisconsin breast cancer dataset
Note that each of these functions begins with the word load. When you see this formulation in Python, the chances are good that the associated dataset is one of the Scikit-learn toy datasets.
The technique for loading each of these datasets is the same across examples. The following example shows how to load the Boston house-prices dataset:from sklearn.datasets import load_boston Boston = load_boston() print(Boston.data.shape)To see how the code works, click Run Cell. The output from the
print() call is (506, 13). You can see the output shown here.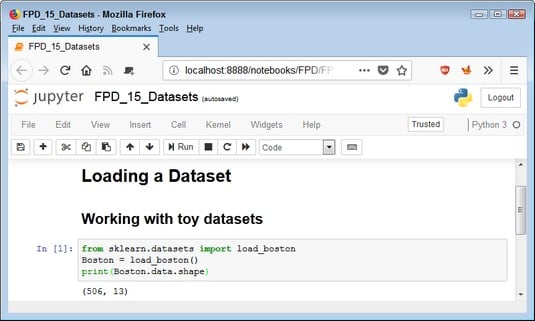 The Boston object contains the loaded dataset.
The Boston object contains the loaded dataset.
Creating custom data for functional programming
The purpose of each of the data generator functions is to create randomly generated datasets that have specific attributes. For example, you can control the number of data points using then_samples argument and use the centers argument to control how many groups the function creates within the dataset. Each of the calls starts with the word make. The kind of data depends on the function; for example, make_blobs() creates Gaussian blobs for clustering. The various functions reflect the kind of labeling provided: single label and multilabel. You can also choose bi-clustering, which allows clustering of both matrix rows and columns. Here's an example of creating custom data:
from sklearn.datasets import make_blobs X, Y = make_blobs(n_samples=120, n_features=2, centers=4) print(X.shape)The output will tell you that you have indeed created an X object containing a dataset with two features and 120 cases for each feature. The Y object contains the color values for the cases. Seeing the data plotted using the following code is more interesting:
import matplotlib.pyplot as plt %matplotlib inline plt.scatter(X[:, 0], X[:, 1], s=25, c=Y) plt.show()In this case, you tell Notebook to present the plot inline. The output is a scatter chart using the x-axis and y-axis contained in
X. The c=Y argument tells scatter() to create the chart using the color values found in Y. Notice that you can clearly see the four clusters based on their color.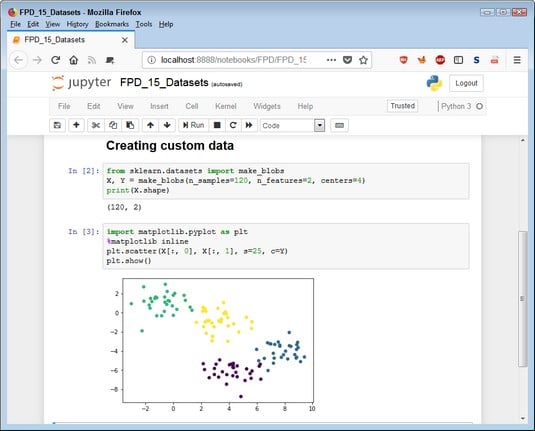 Custom datasets provide randomized data output in the form you specify and can be very useful in functional programming.
Custom datasets provide randomized data output in the form you specify and can be very useful in functional programming.
Fetching common datasets for functional programming
At some point, you need larger datasets of common data to use for testing. The toy datasets that worked fine when you were testing your functions may not do the job any longer. Python provides access to larger datasets that help you perform more complex testing but won’t require you to rely on network sources. These datasets will still load on your system so that you’re not waiting on network latency during testing. Consequently, they’re between the toy datasets and a real-world dataset in size. More important, because they rely on actual (standardized) data, they reflect real-world complexity. The following list tells you about the common datasets:fetch_olivetti_faces(): Olivetti faces dataset from AT&T containing ten images each of 40 different test subjects; each grayscale image is 64 x 64 pixels in sizefetch_20newsgroups(<em>subset='train'</em>): Data from 18,000 newsgroup posts based on 20 topics, with the dataset split into two subgroups: one for training and one for testingfetch_mldata(<em>'MNIST original'</em>, <em>data_home=custom_data_home</em>): Dataset containing machine learning data in the form of 70,000, 28-x-28-pixel handwritten digits from 0 through 9fetch_lfw_people(min_faces_per_person=70, resize=0.4): Labeled Faces in the Wild dataset, which contains pictures of famous people in JPEG formatdatasets.fetch_covtype(): U.S. forestry dataset containing the predominant tree type in each of the patches of forest in the datasetdatasets.fetch_rcv1(): Reuters Corpus Volume I (RCV1) is a dataset containing 800,000 manually categorized stories from Reuters, Ltd.
from sklearn.datasets import fetch_olivetti_faces data = fetch_olivetti_faces() print(data.images.shape)When you run this code, you see that the shape is 400 images, each of which is 64 x 64 pixels. The resulting
data object contains a number of properties, including images. To access a particular image, you use data.images[<em>?</em>], where ? is the number of the image you want to access in the range from 0 to 399. Here is an example of how you can display an individual image from the dataset.
import matplotlib.pyplot as plt %matplotlib inline plt.imshow(data.images[1], cmap="gray") plt.show()The
cmap argument tells how to display the image, which is in grayscale in this case. This tutorial provides additional information on using cmap, as well as on adjusting the image in various ways.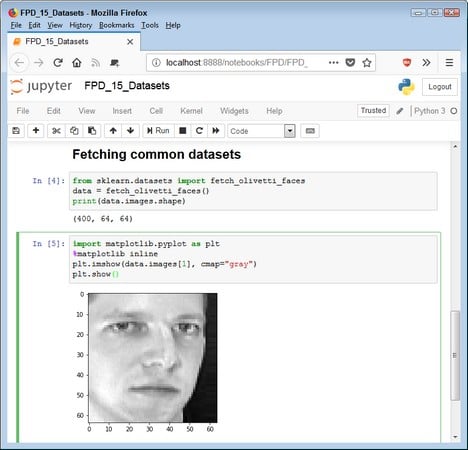 The image appears as a 64-x-64-pixel matrix.
The image appears as a 64-x-64-pixel matrix.