
The data resides in an R package called titanic. If it’s not already on the Packages tab, click Install. In the Install Packages dialog box, type titanic and click the Install button. After the package downloads, find it on the Packages tab and select its check box.
In the titanic package, you’ll find titanic_train and titanic_test. Don’t be tempted to use one as the training set and the other as the test set for this particular application of Rattle. The titanic_test set doesn’t include the Survived variable, so it’s not usable for testing a decision tree the way I lay out the process here.
Instead, create the data frame like this:
library(titanic)
titanic.df <- titanic_train
Then use Rattle’s Data tab to read in the dataset. This image shows what the Data tab looks like after a few modifications.
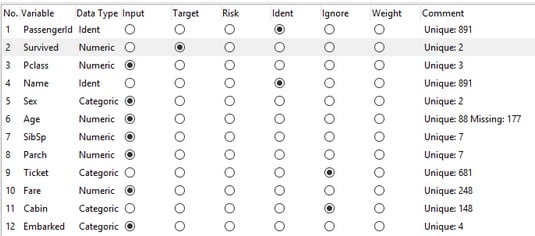 The
The Rattle Data tab, after modifying the titanic.df dataset.What are those modifications? First, a rule of thumb: If a variable is categoric and has a lot of unique values (and if it’s not already classified as an Ident (identifier)), click its Ignore radio button. Also, when first encountering this dataset, Rattle thinks Embarked is the target variable. Use the radio buttons to change Embarked to Categoric and to change Survived to Target.
Good luck!