Understanding similarity
In a vector form, you can see each variable in your examples as a series of coordinates, with each one pointing to a position in a different space dimension. If a vector has two elements, that is, it has just two variables, working with it is just like checking an item’s position on a map by using the first number for the position on the East-West axis and the second on the North-South axis.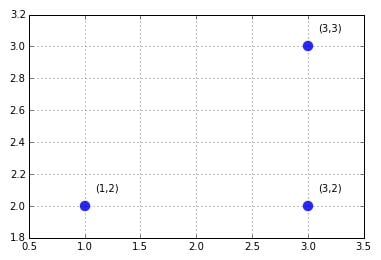
For instance, the numbers between parentheses (1,2) (3,2), and (3,3) are all examples of points. Each example is an ordered list of values (called a tuple) that can be easily located and printed on a map using the first value of the list for x (the horizontal axis) and the second for y (the vertical axis). The result is a scatterplot.
If your data set, in matrix form, has many numeric features (the columns), ideally the number of the features represents the dimensions of the data space, while the rows (the examples) represent each point, which mathematically is a vector. When your vector has more than two elements, visualization becomes troublesome because representing dimensionalities above the third isn’t easy (after all, we live in a three-dimensional world).
However, you can strive to convey more dimensionalities by some expedient, such as by using size, shape, or color for other dimensions. Clearly, that’s not an easy task, and often the result is far from being intuitive. However, you can grasp the idea of where the points would be in your data space by systematically printing many graphs while considering the dimensions two by two. Such plots are called matrices of scatterplots.
Don’t worry about multidimensionality. You extend the rules you learned in two or three dimensions to multiple dimensions, so if a rule works in a bidimensional space, it also works in a multiple one. Therefore all the examples first refer to bidimensional examples.
Computing distances for learning
An algorithm can learn by using vectors of numbers that use distance measurements. Often the space implied by your vectors is a metric one that is a space whose distances respect certain specific conditions:- No negative distances exist, and your distance is zero only when the starting point and ending point coincide (called nonnegativity).
- The distance is the same going from a point to another and vice versa (called symmetry).
- The distance between an initial point and a final one is always greater than, or at worse the same as, the distance going from the initial to a third point and from there to the final one (called triangle inequality — which means that there are no shortcuts).
Euclidean distance
The most common is the Euclidean distance, also described as the l2 norm of two vectors (read this discussion of l1, l2, and linfinity norms). In a bidimensional plane, the Euclidean distance refigures as the straight line connecting two points, and you calculate it as the square root of the sum of the squared difference between the elements of two vectors. In the previous plot, the Euclidean distance between points (1,2) and (3,3) can be computed in R as sqrt((1-3)^2+(2-3)^2), which results in a distance of about 2.236.Manhattan distance
Another useful measure is the Manhattan distance (also described as the l1 norm of two vectors). You calculate the Manhattan distance by summing the absolute value of the difference between the elements of the vectors. If the Euclidean distance marks the shortest route, the Manhattan distance marks the longest route, resembling the directions of a taxi moving in a city. (The distance is also known as taxicab or city-block distance.)For instance, the Manhattan distance between points (1,2) and (3,3) is abs(1–3) and abs(2–3), which results in 3.
Chebyshev distance
The Chebyshev distance or maximum metric takes the maximum of the absolute difference between the elements of the vectors. It is a distance measure that can represent how a king moves in the game of chess or, in warehouse logistics, the operations required by an overhead crane to move a crate from one place to another.In machine learning, the Chebyshev distance can prove useful when you have many dimensions to consider and most of them are just irrelevant or redundant (in Chebyshev, you just pick the one whose absolute difference is the largest). In the example used in above, the distance is simply 2, the max between (1–3) and abs(2–3).