The objective of a supervised classifier is to assign a class to an example after having examined some characteristics of the example itself. Such characteristics are called features, and they can be both quantitative (numeric values) or qualitative (string labels). To assign classes correctly, the classifier must first closely examine a certain number of known examples (examples that already have a class assigned to them), each one accompanied by the same kinds of features as the examples that don’t have classes.
The training phase involves observation of many examples by the classifier that helps it learn so that it can provide an answer in terms of a class when it sees an example without a class later.
To give an idea of what happens in the training process, imagine a child learning to distinguish trees from other objects. Before the child can do so in an independent fashion, a teacher presents the child with a certain number of tree images, complete with all the facts that make a tree distinguishable from other objects of the world.Such facts could be features such as its material (wood), its parts (trunk, branches, leaves or needles, roots), and location (planted into the soil). The child produces an idea of what a tree looks like by contrasting the display of tree features with the images of other different objects, such as pieces of furniture that are made of wood but do not share other characteristics with a tree.
A machine learning classifier works in the same way. It builds its cognitive capabilities by creating a mathematical formulation that includes all the given features in a way that creates a function that can distinguish one class from another.
Pretend that a mathematical formulation, also called target function, exists to express the characteristics of a tree. In such a case, a machine learning classifier can look for its representation as a replica or as an approximation (a different function that works alike). Being able to express such mathematical formulation is the representation capability of the classifier.
From a mathematical perspective, you can express the representation process in machine learning using the equivalent term mapping. Mapping happens when you discover the construction of a function by observing its outputs. A successful mapping in machine learning is similar to a child internalizing the idea of an object. She understands the abstract rules derived from the facts of the world in an effective way so that when she sees a tree, for example, she immediately recognizes it.
Such a representation (abstract rules derived from real-world facts) is possible because the learning algorithm has many internal parameters (constituted of vectors and matrices of values), which equate to the algorithm’s memory for ideas that are suitable for its mapping activity that connects features to response classes. The dimensions and type of internal parameters delimit the kind of target functions that an algorithm can learn. An optimization engine in the algorithm changes parameters from their initial values during learning to represent the target’s hidden function.During optimization, the algorithm searches among the possible variants of its parameter combinations in order to find the one that best allows the correct mapping between the features and classes during training. This process evaluates many potential candidate target functions from among those that the learning algorithm can guess.
The set of all the potential functions that the learning algorithm can figure out is called the hypothesis space. You can call the resulting classifier with all its set parameters a hypothesis, a way in machine learning to say that the algorithm has set parameters to replicate the target function and is now ready to work out correct classifications.
The hypothesis space must contain all the parameter variants of all the machine learning algorithms that you want to try to map to an unknown function when solving a classification problem. Different algorithms can have different hypothesis spaces. What really matters is that the hypothesis space contains the target function (or its approximation, which is a different but similar function).
You can imagine this phase as the time when a child, in an effort to figure out her own idea of a tree, experiments with many different creative ideas by assembling her own knowledge and experiences (an analogy for the given features). Naturally, the parents are involved in this phase, and they provide relevant environmental inputs.In machine learning, someone has to provide the right learning algorithms, supply some nonlearnable parameters (called hyper-parameters), choose a set of examples to learn from, and select the features that accompany the examples. Just as a child can’t always learn to distinguish between right and wrong if left alone in the world, so machine learning algorithms need human beings to learn successfully.
Even after completing the learning process, a machine learning classifier often can’t univocally map the examples to the target classification function because many false and erroneous mappings are also possible.
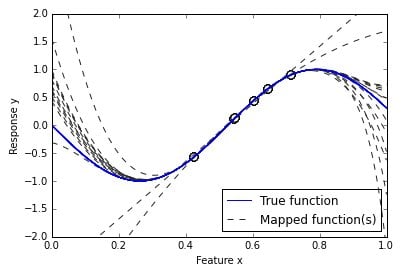
In many cases, the algorithm lacks enough data points to discover the right function. Noise mixed with the data can also cause problems.
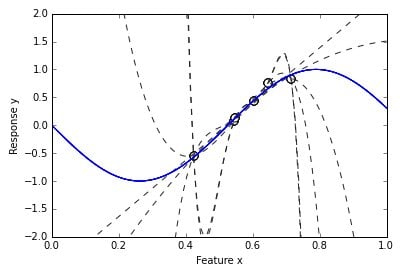
Noise in real-world data is the norm. Many extraneous factors and errors that occur when recording data distort the values of the features. A good machine learning algorithm should distinguish the signals that can map back to the target function from extraneous noise.