
When you are data mining, sometimes you’ll have more data than you need for a given project. Here’s how to pare down to just what you need.
Narrowing the fields
When you have many variables in a dataset, it can be hard to find or see the ones that interest you. And if your datasets are large, and you don’t need all the variables, keeping the extras soaks up resources unnecessarily. So, you sometimes need to keep some variables and drop others. The figure shows an example in KNIME, where the right tool is called Column Filter.
An example setup for this tool is shown in the following figure.
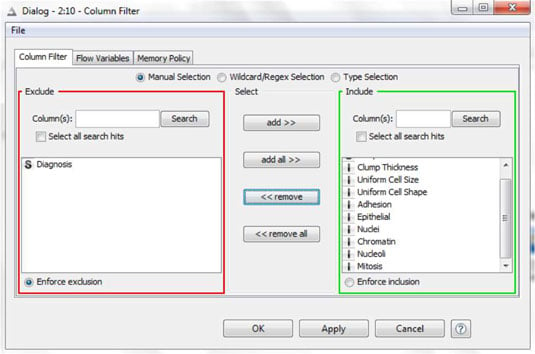
To narrow the fields, look for a variable selection tool in your data-mining application; these are found with other tools for data manipulation. As with other data-mining tools, the names vary from product to product. Look for variations on the words column, variable, or field, and selection or filtering.
Selecting relevant cases
Cases with incomplete data can be filtered out before building the model. Removing incomplete cases is one common example of data selection, or filtering.
But how would you select only the relevant cases for each segment that interests you? You’d use a data selection tool.
The following figure shows a data selection tool in another data-mining application.
The next figure shows how you’d set up that tool for another kind of selection, this one based on the value of a variable.
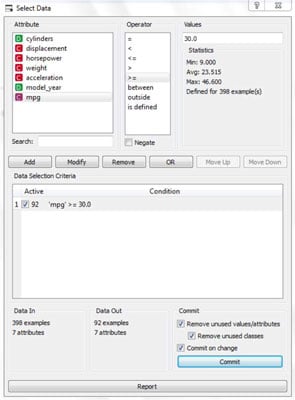
It’s common to use this kind of data selection, and some applications provide all sorts of built-in functions to help you define exactly the cases you want. This one has some exceptional features; it displays summary statistics for the variable and tells you exactly how many cases meet the selection criteria.
Most data-mining applications have tools for selecting just the cases you need. Look in the menus (or search) for select or filter.
Sampling
A popular notion these days is that more data is better data. This is not a new idea. Data-mining applications have always been developed to work with large quantities of data. Even the name “data mining” suggests large quantities. But often, working with a sample of your data will give you information that is just as useful, make your work easier, and conserve your time and resources.
Sampling plays important roles in data mining. If the data is balanced that means the model used equal numbers of cases in each of the groups being compared (in that example, the groups were properties that changed hands and properties that did not), even though one group had many more cases than the other in the original data.
Later, the data was split, separated into one subset to use for training a model and another for testing. Using only a sample of data in a parallel coordinates plot can make it easier to view and interpret. (Scatterplots with thousands of points can be impossibly hard to read!) Perhaps most important of all, sampling just reduces the amount of data, so things run faster.