
Data mining has very strict requirements for data organization. They are not exotic, complex, or difficult requirements to meet, but they are strict. The figure shows a sample of data viewed as a table in data-mining software.
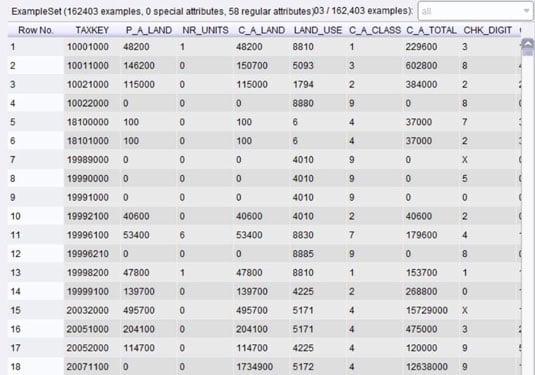
Each row represents one parcel of real estate. Information about the parcels of real estate is organized in columns. The first column contains the tax identification number (TAXKEY), the second column contains the assessed value of the land from a prior assessment (P_A_LAND), and so on.
Every entry in any one row pertains to one specific parcel of land. Every entry in any one column is the same type of information. No rows or columns are left blank for reasons relating to style and readability. This data is properly organized for investigating differences among the parcels of real estate.
If, instead of real estate, you investigate people, each person would be represented by one row in the data, and all the details about the people would be organized into columns. If you investigate chest x-rays, each chest x-ray would be represented by one row in the data, and all the details about the chest x-rays would be organized into columns.
In data analysis terminology, the things you’re studying — the things in the rows — are called cases or records. And the details about them, which are in the columns, are called variables. You will also hear the columns called fields, especially in the context of databases.
So, data mining requires data organized with a single row for each case and a single column for each variable. Many sources of data are already organized in this way. Statisticians organize data this way by habit. Database professionals may not use this approach for much of their work, but they’ll usually understand what you want if you call it a flat table.
You’ll find subtle variations in data structure. Some types of software use descriptive information in a header before the data, such as certain specialty formats associated with the Orange and Weka data-mining applications. Some complex analytic procedures have additional or slightly varied requirements (these are quite unusual). But the core of the data still has the cases in rows and variables in columns.