
A complex algorithm used for predictive analysis, the neural network, is biologically inspired by the structure of the human brain. A neural network provides a very simple model in comparison to the human brain, but it works well enough for our purposes.
Widely used for data classification, neural networks process past and current data to estimate future values — discovering any complex correlations hidden in the data — in a way analogous to that employed by the human brain.
Neural networks can be used to make predictions on time series data such as weather data. A neural network can be designed to detect pattern in input data and produce an output free of noise.
The structure of a neural-network algorithm has three layers:
The input layer feeds past data values into the next (hidden) layer. The black circles represent nodes of the neural network.
The hidden layer encapsulates several complex functions that create predictors; often those functions are hidden from the user. A set of nodes (black circles) at the hidden layer represents mathematical functions that modify the input data; these functions are called neurons.
The output layer collects the predictions made in the hidden layer and produces the final result: the model’s prediction.
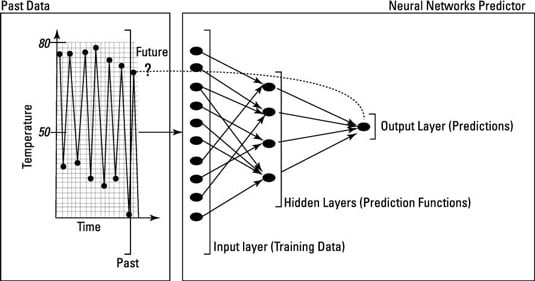
Here’s a closer look at how a neural network can produce a predicted output from input data. The hidden layer is the key component of a neural network because of the neurons it contains; they work together to do the major calculations and produce the output.
Each neuron takes a set of input values; each is associated with a weight (more about that in a moment) and a numerical value known as bias. The output of each neuron is a function of the output of the weighted sum of each input plus the bias.
Most neural networks use mathematical functions to activate the neurons. A function in math is a relation between a set of inputs and a set of outputs, with the rule that each input corresponds to an output.
For instance, consider the negative function where a whole number can be an input and the output is its negative equivalent. In essence, a function in math works like a black box that takes an input and produces an output.
Neurons in a neural network can use sigmoid functions to match inputs to outputs. When used that way, a sigmoid function is called a logistic function and its formula looks like this:
f(input) = 1/(1+eoutput)
Here f is the activation function that activates the neuron, and e is a widely used mathematical constant that has the approximate value of 2.718.
You might wonder why such a function is used in neurons. Well, most sigmoid functions have derivatives that are positive and easy to calculate. They’re continuous, can serve as types of smoothing functions, and are also bounded functions.
This combination of characteristics, unique to sigmoid functions, is vital to the workings of a neural network algorithm — especially when a derivative calculation — such as the weight associated with each input to a neuron — is needed.
The weight for each neuron is a numerical value that can be derived using either supervised training or unsupervised training such as data clustering.
In the case of supervised training, weights are derived by feeding sample inputs and outputs to the algorithm until the weights are tuned (that is, there’s a near-perfect match between inputs and outputs).
In the case of unsupervised training, the neural network is only presented with inputs; the algorithm generates their corresponding outputs. When the algorithms are presented with new-but-similar inputs and the algorithm produces new outputs that are similar to previous outputs, then the neurons’ weights have been tuned.
Neural networks tend to have high accuracy even if the data has a significant amount of noise. That’s a major advantage; when the hidden layer can still discover relationships in the data despite noise, you may be able to use otherwise-unusable data.
One disadvantage of the neural-network algorithms is that the accuracy of the prediction may be valid only within the time period during which the training data was gathered.