
Data scientists often refer to the technology used to implement machine learning as algorithms. An algorithm is a series of step-by-step operations, usually computations, that can solve a defined problem in a finite number of steps. In machine learning, the algorithms use a series of finite steps to solve the problem by learning from data.
Understanding how machine learning works
Machine learning algorithms learn, but it’s often hard to find a precise meaning for the term learning because different ways exist to extract information from data, depending on how the machine learning algorithm is built. Generally, the learning process requires huge amounts of data that provides an expected response given particular inputs. Each input/response pair represents an example and more examples make it easier for the algorithm to learn. That’s because each input/response pair fits within a line, cluster, or other statistical representation that defines a problem domain.Machine learning is the act of optimizing a model, which is a mathematical, summarized representation of data itself, such that it can predict or otherwise determine an appropriate response even when it receives input that it hasn’t seen before. The more accurately the model can come up with correct responses, the better the model has learned from the data inputs provided. An algorithm fits the model to the data, and this fitting process is training.
The image below shows an extremely simple graph that simulates what occurs in machine learning. In this case, starting with input values of 1, 4, 5, 8, and 10 and pairing them with their corresponding outputs of 7, 13, 15, 21, and 25, the machine learning algorithm determines that the best way to represent the relationship between the input and output is the formula 2x + 5. This formula defines the model used to process the input data — even new, unseen data —to calculate a corresponding output value. The trend line (the model) shows the pattern formed by this algorithm, such that a new input of 3 will produce a predicted output of 11. Even though most machine learning scenarios are much more complicated than this (and the algorithm can't create rules that accurately map every input to a precise output), the example gives provides you a basic idea of what happens. Rather than have to individually program a response for an input of 3, the model can compute the correct response based on input/response pairs that it has learned.
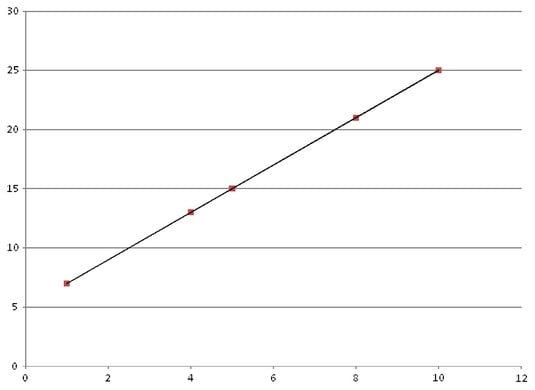 Visualizing a basic machine learning scenario.
Visualizing a basic machine learning scenario.
Understanding that machine learning is pure math
The central idea behind machine learning is that you can represent reality by using a mathematical function that the algorithm doesn’t know in advance, but which it can guess after seeing some data (always in the form of paired inputs and outputs). You can express reality and all its challenging complexity in terms of unknown mathematical functions that machine learning algorithms find and make available as a modification of their internal mathematical function. That is, every machine learning algorithm is built around a modifiable math function. The function can be modified because it has internal parameters or weights for such a purpose. As a result, the algorithm can tailor the function to specific information taken from data. This concept is the core idea for all kinds of machine learning algorithms.Learning in machine learning is purely mathematical, and it ends by associating certain inputs with certain outputs. It has nothing to do with understanding what the algorithm has learned. (When humans analyze data, we build an understanding of the data to a certain extent.) The learning process is often described as training because the algorithm is trained to match the correct answer (the output) to every question offered (the input). (Machine Learning For Dummies, by John Paul Mueller and Luca Massaron, describes how this process works in detail.)
In spite of lacking deliberate understanding and of being a mathematical process, machine learning can prove useful in many tasks. It provides many AI applications the power to mimic rational thinking given a certain context when learning occurs by using the right data.
Different strategies for machine learning
Machine learning offers a number of different ways to learn from data. Depending on your expected output and on the type of input you provide, you can categorize algorithms by learning style. The style you choose depends on the sort of data you have and the result you expect. The four learning styles used to create algorithms are:- Supervised machine learning
- Unsupervised machine learning
- Self-supervised machine learning
- Reinforcement machine learning
Supervised machine learning
When working with supervised machine learning algorithms, the input data is labeled and has a specific expected result. You use training to create a model that an algorithm fits to the data. As training progresses, the predictions or classifications become more accurate. Here are some examples of supervised machine learning algorithms:- Linear or Logistic regression
- Support Vector Machines (SVMs)
- Naïve Bayes
- K-Nearest Neighbors (KNN)
| Data Input (X) | Data Output (y) | Real-World Application |
| History of customers’ purchases | A list of products that customers have never bought | Recommender system |
| Images | A list of boxes labeled with an object name | Image detection and recognition |
| English text in the form of questions | English text in the form of answers | Chatbot, a software application that can converse |
| English text | German text | Machine language translation |
| Audio | Text transcript | Speech recognition |
| Image, sensor data | Steering, braking, or accelerating | Behavioral planning for autonomous driving |
Unsupervised machine learning
When working with unsupervised machine learning algorithms, the input data isn’t labeled and the results aren’t known. In this case, analysis of structures in the data produces the required model. The structural analysis can have a number of goals, such as to reduce redundancy or to group similar data. Examples of unsupervised machine learning are- Clustering
- Anomaly detection
- Neural networks
Self-Supervised machine learning
You’ll find all sorts of kinds of learning described online, but self-supervised learning is in a category of its own. Some people describe it as autonomous supervised learning, which gives you the benefits of supervised learning but without all the work required to label data.Theoretically, self-supervised could solve issues with other kinds of learning that you may currently use. The following list compares self-supervised learning with other sorts of learning that people use.
- Supervised machine learning: The closest form of learning associated with self-supervised learning is supervised machine learning because both kinds of learning rely on pairs of inputs and labeled outputs. In addition, both forms of learning are associated with regression and classification. However, the difference is that self-supervised learning doesn’t require a person to label the output. Instead, it relies on correlations, embedded metadata, or domain knowledge embedded within the input data to contextually discover the output label.
- Unsupervised machine learning: Like unsupervised machine learning, self-supervised learning requires no data labeling. However, unsupervised learning focuses on data structure — that is, patterns within the data. Therefore, you don’t use self-supervised learning for tasks such as clustering, grouping, dimensionality reduction, recommendation engines, or the like.
- Semi-supervised machine learning: A semi-supervised learning solution works like an unsupervised learning solution in that it looks for data patterns. However, semi-supervised learning relies on a mix of labeled and unlabeled data to perform its tasks faster than is possible using strictly unlabeled data. Self-supervised learning never requires labels and uses context to perform its task, so it would actually ignore the labels when supplied.
Reinforcement machine learning
You can view reinforcement learning as an extension of self-supervised learning because both forms use the same approach to learning with unlabeled data to achieve similar goals. However, reinforcement learning adds a feedback loop to the mix. When a reinforcement learning solution performs a task correctly, it receives positive feedback, which strengthens the model in connecting the target inputs and output. Likewise, it can receive negative feedback for incorrect solutions. In some respects, the system works much the same as working with a dog based on a system of rewards.Training, validating, and testing data for machine learning
Machine learning is a process, just as everything is a process in the world of computers. To build a successful machine learning solution, you perform these tasks as needed, and as often as needed:- Training: Machine learning begins when you train a model using a particular algorithm against specific data. The training data is separate from any other data, but it must also be representative. If the training data doesn’t truly represent the problem domain, the resulting model can’t provide useful results. During the training process, you see how the model responds to the training data and make changes, as needed, to the algorithms you use and the manner in which you massage the data prior to input to the algorithm.
- Validating: Many datasets are large enough to split into a training part and a testing part. You first train the model using the training data, and then you validate it using the testing data. Of course, the testing data must again represent the problem domain accurately. It must also be statistically compatible with the training data. Otherwise, you won’t see results that reflect how the model will actually work.
- Testing: After a model is trained and validated, you still need to test it using real-world data. This step is important because you need to verify that the model will actually work on a larger dataset that you haven’t used for either training or testing. As with the training and validation steps, any data you use during this step must reflect the problem domain you want to interact with using the machine learning model.
To give an idea of what happens in the training process, imagine a child learning to distinguish trees from objects, animals, and people. Before the child can do so in an independent fashion, a teacher presents the child with a certain number of tree images, complete with all the facts that make a tree distinguishable from other objects of the world. Such facts could be features, such as the tree’s material (wood), its parts (trunk, branches, leaves or needles, roots), and location (planted in the soil). The child builds an understanding of what a tree looks like by contrasting the display of tree features with the images of other, different examples, such as pieces of furniture that are made of wood, but do not share other characteristics with a tree.
A machine learning classifier works the same. A classifier algorithm provides you with a class as output. For instance, it could tell you that the photo you provide as an input matches the tree class (and not an animal or a person). To do so, it builds its cognitive capabilities by creating a mathematical formulation that includes all the given input features in a way that creates a function that can distinguish one class from another.
Looking for generalization in machine learning
To be useful, a machine learning model must represent a general view of the data provided. If the model doesn’t follow the data closely enough, it’s underfitted — that is, not fitted enough because of a lack of training. On the other hand, if the model follows the data too closely, it’s overfitted, following the data points like a glove because of too much training. Underfitting and overfitting both cause problems because the model isn’t generalized enough to produce useful results. Given unknown input data, the resulting predictions or classifications will contain large error values. Only when the model is correctly fitted to the data will it provide results within a reasonable error range.This whole issue of generalization is also important in deciding when to use machine learning. A machine learning solution always generalizes from specific examples to general examples of the same sort. How it performs this task depends on the orientation of the machine learning solution and the algorithms used to make it work.
The problem for data scientists and others using machine learning and deep learning techniques is that the computer won’t display a sign telling you that the model correctly fits the data. Often, it’s a matter of human intuition to decide when a model is trained enough to provide a good generalized result. In addition, the solution creator must choose the right algorithm out of the thousands that exist. Without the right algorithm to fit the model to the data, the results will be disappointing. To make the selection process work, the data scientist must possess
- A strong knowledge of the available machine learning algorithms
- Experience dealing with the kind of data in question
- An understanding of the desired output
- A desire to experiment with various machine learning algorithms
Getting to know the limits of bias
Your computer has no bias. It has no goal of world domination or of making your life difficult. In fact, computers don’t have goals of any kind. The only thing a computer can provide is output based on inputs and processing technique. However, bias still gets into the computer and taints the results it provides in a number of ways:- Data: The data itself can contain mistruths or simply misrepresentations. For example, if a particular value appears twice as often in the data as it does in the real world, the output from a machine learning solution is tainted, even though the data itself is correct.
- Algorithm: Using the wrong algorithm will cause the machine learning solution to fit the model to the data incorrectly.
- Training: Too much or too little training changes how the model fits the data and therefore the result.
- Human interpretation: Even when a machine learning solution outputs a correct result, the human using that output can misinterpret it. The results are every bit as bad as, and perhaps worse than, when the machine learning solution fails to work as anticipated.
Keeping model complexity in mind for machine learning
Simpler is always better when it comes to machine learning. Many different algorithms may provide you with useful output from your machine learning solution, but the best algorithm to use is the one that’s easiest to understand and provides the most straightforward results. Occam’s Razor is generally recognized as the best strategy to follow. Basically, Occam’s Razor tells you to use the simplest solution that will solve a particular problem. As complexity increases, so does the potential for errors.The most important guiding factor when selecting an algorithm should be simplicity.