
Before attempting some hard-and-fast role definitions of these data science careers, then, let’s start by sketching out the different task sets you'd typically find on a data science team. The idea here is to scope the high-level competence areas that need to be covered on a data science team, regardless of who actually carries out which task. The three main data science careers are mathematics/statistics, computer science, and business domain knowledge.
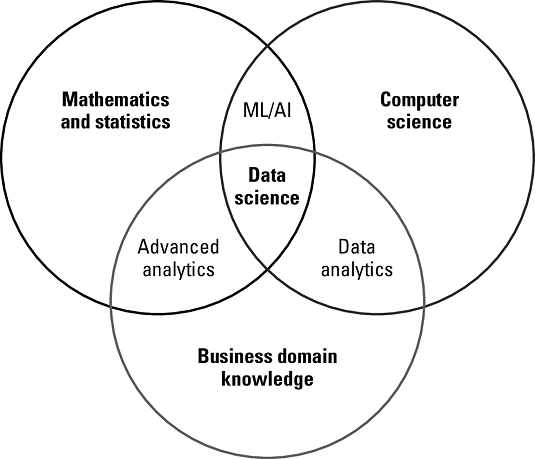 Competence areas needed on a data science team.
Competence areas needed on a data science team.The image above shows the easy part because there's general agreement on which competencies are required for a successful and efficient data science careers — though you still need to define the roles and areas of responsibility for each team member. The definitions of data science careers that you find here aim to give you a general understanding of the most important roles you’ll need on your data science team. Just remember that variants may apply, depending on your own specific setup and strategic focus.
Data scientist
In general terms, a data scientist produces mathematical models for the purposes of prediction. And, because the development and interpretation of mathematical models requires deep technical knowledge, most data scientists have graduate level training in computer science, mathematics, or statistics. Data scientists also need strong programming skills in order to effectively leverage the range of available software tools. Aside from being technically savvy, data scientists need critical thinking skills, based on common sense as well as on a thorough understanding of a company's business objectives in order to produce high quality models.Sometimes, a role referred to as data analyst is set apart from the data scientist role. In such cases, the data analyst role is like the Sherlock Holmes of the data science team in that they focus on collecting and interpreting data as well as analyzing patterns and trends in the data which they draw conclusions from in a business context. The data analyst must master languages like R, Python, SQL, and C, and, just like the data scientist, the skills and talents that are needed for this role are diverse and span the entire spectrum of tasks in the data science process. And, to top it all off, a data analyst must demonstrate a healthy I-can-figure-it-out attitude. It’s really up to you to decide whether you want to have all your company’s data scientists take up the tasks associated with a data analyst or if you want to set up a data analyst as a separate role.
Within the role of the data scientist, you'll find another, more traditional role hidden away: the statistician. In historical terms, the statistician was the leader when it came to data and the insights it could provide. Although often forgotten or replaced by fancier-sounding job titles, the statistician role represents what the data science field stands for: getting useful insights from data. With their strong background in statistical theories and methodologies, and a logically oriented mindset, statisticians harvest the data and turn it into information and knowledge. They can handle all sorts of data. What’s more, thanks to the quantitative background, modern statisticians are often able to quickly master new technologies and use these to boost their intellectual capacities. A statistician brings to the table the magic of mathematics with insights that have the ability to radically transform businesses.Data engineer
The role of the data engineer is fundamental for data science. Without data, there cannot be any data science, and the job of data scientists is a) quite impossible if the requisite data isn’t available and b) definitely daunting if the data is available but only on an inconsistent basis. The problem of inconsistency is frequently faced by data scientists, who often complain that too much of their time is spent on data acquisition and cleaning. That’s where the data engineer comes in: This person’s role is to create consistent and easily accessible data pipelines for consumption by data scientists. In other words, data engineers are responsible for the mechanics of data ingestion, processing, and storage, all of which should be invisible to the data scientists.If you’re dealing with small data sets, data engineering essentially consists of entering some numbers into a spreadsheet. When you operate at a more impressive scale, data engineering becomes a sophisticated discipline in its own right. Someone on your team looking for a data science career will need to take responsibility for dealing with the tricky engineering aspects of delivering data that the rest of your staff can work with.
Data engineers don’t need to know anything about machine learning (ML) or statistics to be successful. They don’t even need to be inside the core data science team, but could be part of a larger, separate data engineering team that supplies data to all data science teams. However, you should never place your data engineers and data scientists too far apart from one other organizationally. If these roles are separated into different organizations, with potentially different priorities, this could heavily impact the data science team productivity. Data science methods are quite experimental and iterative in nature, which means that it must be possible to continuously modify data sets as the analysis and algorithm development progress. For that to happen, data scientists need to be able to rely on a prompt response from the data engineers if trouble arises. Without that rapid response, you run the risk of slowing down a data science team's productivity.
Machine learning engineer
Data scientists build mathematical models, and data engineers make data available to data scientists as the “raw material” from which mathematical models are derived. To complete the picture, these models must first be deployed (put into operation, in other words), and, second, they must be able to act on the insights gained from data analysis in order to produce business value. This task is the purview of the machine learning engineer.The machine learning engineer role is a software engineering role, with the difference that the ML engineer has considerable expertise in data science. This expertise is required because ML engineers bridge the gap between the data scientists and the broader software engineering organization. With ML engineers dedicated to model deployment, the data scientists are free to continually develop and refine their models.
Variants are always a possibility when setting up a data science team. For example, the ML engineer deployment responsibilities are often also handled by the data scientist role. Depending on the importance of the operational environment for your specific business, it can make more or less sense to separate this role from the data scientist responsibilities. It is, again, up to you to implement this responsibility within the team.
Data architect
A data architecture is a set of rules, policies, standards and models that govern and define the type of data collected and how it is used, stored, managed and integrated within an organization and its data systems. The person charged with designing, creating, deploying, and managing an organization's data architecture is called a data architect, and they definitely need to be accounted for on the data science team.Data architects define how the data will be stored, consumed, protected, integrated, and managed by different data entities and IT systems, as well as any applications using or processing that data in some way. A data architect usually isn’t a permanent member of a single data science team, but rather serves several data science teams, working closely with each team to ensure efficiency and high productivity.
Business analyst
The business analyst often comes from a different background when compared to the rest of the team. Though often less technically oriented, business analysts make up for it with their deep knowledge of the different business processes running through the company — operational processes (the sales process), management processes (the budget process) and supporting processes (the hiring process). The business analyst masters the skill of linking data insights to actionable business insights and can use storytelling techniques to spread the message across the entire organization. This person often acts as the intermediary between the "business guys" and the "techies."Software engineer
The main role of a software engineer on a data science team is to secure more structure in the data science work so that it becomes more applied and less experimental in nature. The software engineer has an important role in terms of collaborating with the data scientists, data architects, and business analysts to ensure alignment between the business objectives and the actual solution. You could say that a software engineer is responsible for bringing a software engineering culture into the data science process. That is a massive undertaking, and it involves tasks such as automating the data science team infrastructure, ensuring continuous integration and version control, automating testing, and developing APIs to help integrate data products into various applications.Domain expert
It takes a lot of conversations to make data science work. Data scientists can't do it on their own. Success in data science requires a multiskilled project team with data scientists and domain experts working closely together. The domain expert brings the technical understanding of her area of expertise, sometimes combined with a thorough business understanding of that area as well. It usually includes familiarity with the basics of data analysis, which means that domain experts can support many roles on the data science team. However, the domain expert usually isn’t a permanent member of a data science team; more often than not, that person is brought in for specific tasks, like validating data or providing analysis or insight from an expert perspective. Sometimes the domain expert is allocated for longer periods to a certain team, depending on the task and focus. Sometimes one or several domain experts are assigned to support multiple teams at the same time.Characteristics of a great data scientist, the foundational data science career
There’s a lot of promise connected with the data scientist role. The problem is not only that the perfect data scientist doesn’t exist, but also that the few truly skilled ones are too few and too difficult to get hold of in the current marketplace. So, what should you be doing instead of searching for the perfect data scientist?The focus should be on finding someone with the ability to solve the specific problems your company is focusing on — or, to be even more specific, what your own data science team is focusing on. It’s not about hiring the perfect data scientist and hoping that they’re going to do all the things that you need done, now and in the future. Instead, it’s better to hire someone with the specific skills needed to meet the clearly defined organizational objectives you know of today.
For instance, think about whether your need is more related to ad hoc data analysis or product development. Companies that have a greater need for ad hoc data insights should look for data scientists with a flexible and experimental approach and an ability to communicate well with the business side of the organization. On the other hand, if product development is more important in relation to the problems you’re trying to solve, you should look for strong software engineering skills, with a firm base in the engineering process in combination with their analytical skills.If you're hoping to find a handy checklist of all the critical skills that you should be looking for when hiring a data scientist, you'll be sorely disappointed. The fact is, not even a basic description of important traits the role should possess is agreed on across the industry. There are many opinions and ideas about it, but again the lack of standardization is troublesome.
So, what makes coming up with a simple checklist of the needed tool sets, competencies, and technical skills required so difficult? For one, data science careers are evolving fast, and tools and techniques that were important to master last year might be less important this year. Therefore, staying in tune with the evolution of the field and continually learning new methods, tools, and techniques is the key in this space.Another reason it’s difficult to specify a concrete checklist of skills is because the critical skill sets needed are actually outside the data science area — they qualify more as soft skills, like interpersonal communication and projecting the right attitude. Just look at the data scientist Venn diagram of skills, traits, and attitude needed. The variety of skill sets and mindset traits that a perfect data scientist must master is almost ridiculous.
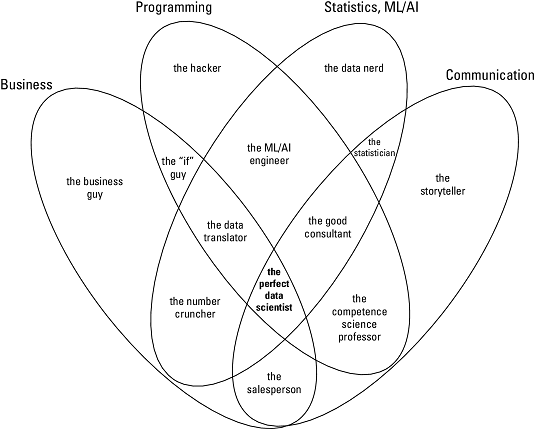 A data scientist Venn diagram of skills, traits, and attitude needed.
A data scientist Venn diagram of skills, traits, and attitude needed.So, bearing in mind that specifying competencies needed for a data scientist is more a question of attitude and mindset in combination with a certain skill set, here’s a list of characteristics that define a good data scientist:
- Business understanding: Having the ability to translate a problem from business language into a hypothesis is important and refers to how a data scientist should be able to understand what the business person describes, and then be able to translate that into technical terms and present a potential solution in that context.
- Impactful versus interesting: Data scientists must be able to resist the temptation to always prioritize the interesting problems when there might be problems that are more important to solve because of the major business impact such solutions would have.
- Curiosity: Having an intellectual curiosity and the ability to detail a problem into a clear set of hypotheses that can be tested is a major plus.
- Attention to detail: As a data scientist, pay attention to details from a technical perspective. A model cannot be nearly right. Building an advanced technical algorithm takes time and dedication to detail.
- Easy learner: The data scientist must have an ability to learn quickly, because the rapidly changing nature of the data science space includes technologies and methodologies but also new tools and open-source models that are made available and become ready to build on.
- Agile mindset: Stay flexible and agile in terms of what is possible, how problems are approached, how solutions are investigated, and how problems are solved.
- Experimentation mindset: The data scientist must not fear to fail or try assumptions that might be wrong in order to find the most successful way forward.
- Communication: A data scientist must be able to tell a story and describe the problem in focus or the opportunity that he’s aiming for, as well as describe how great the models are once they are finished and what they actually enable.
After your team of data scientists is in place, encourage their professional development and lifelong learning. Many data scientists have an academic mindset and a willingness to experiment, but in the pursuit of a perfect solution, they sometimes get lost among all the data and the problems they’re trying to solve. Therefore, it’s important that they stay connected with the team, though you should allow enough independence so that they can continue to publish white papers, contribute to open source, or pursue other meaningful activities in their field.