
Statisticians typically have to look at large masses of data and find hard-to-see patterns. Sometimes an overall trend suggests a particular analytic tool. And sometimes that tool, although statistically powerful, doesn’t help the statistician arrive at an explanation.
The following figure is a chart of home runs hit in the American League from 1901 until 2008.
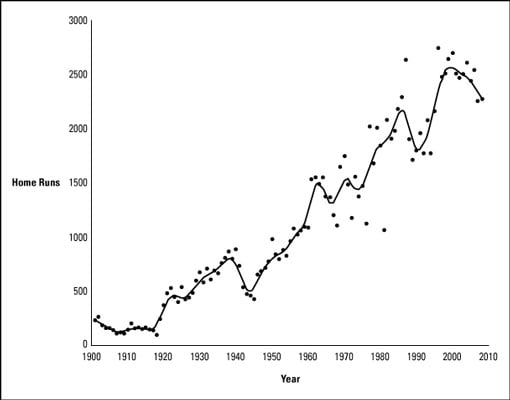
The obvious overall trend is that as the years go by, more home runs are hit. Fitting a regression line confirms this idea. The equation
Home Runs = 24.325*Year – 465395
is a terrific fit to the data. The equation gives an R-Squared value of 0.91, indicating that a linear model nicely describes the relationship between home runs and years.
And so . . . what?
Just fitting a regression line glosses over important things within baseball — things both great and small that make up a baseball season, an era, a history. And baseball has many of those things. The objective is to get them to reveal themselves.
The other extreme from the regression line is to connect the dots. That would just give a bunch of zigzags that likely won’t illuminate a century of history.
The problem is how to summarize without eliminating too much: Get rid of the zigzags but keep the important peaks and valleys. How do you do this without knowing what’s important in advance?
Exploratory data analysis (EDA) helps point the way. One EDA technique is called three-median smoothing. For each data point in a series, replace that data point with the median of three numbers: the data point itself, the data point that precedes it, and the data point that follows.
Why the median? Unlike the mean, the median is not sensitive to extreme values that occur once in awhile — like a zig or a zag. The effect is to filter out the noise and leave meaningful ups and downs.
Why three numbers? Like most everything in EDA, that’s not ironclad. For some sets of data, you might want the median to cover more numbers. It’s up to the intuitions, experiences, and ideas of the analyst.
Another technique, hanning, is a running weighted mean. You replace a data point with the sum of one-fourth the previous data point plus half the data point plus one-fourth the next data point. Still another technique is the skip mean.
In EDA, you don’t just use one technique on a set of data. Often, you start with a median smooth, repeat it several times, and then try one or two others.
For the data in the scatterplot, apply the three-median smooth, repeat it (that is, apply it to the newly smoothed data), han the smoothed data, and then apply the skip mean. Again, no technique (or order of techniques) is right or wrong. You apply what you think illuminates meaningful features of the data.
Following is part of a worksheet for all of this. Column A shows the year, and Column B shows the number of home runs hit that year in the American League. The remaining columns show successive smooths of the data.
Column C applies the three-median smooth to Column B, and Column D applies the three-median smooth to Column C. A quick look at the numbers shows that the repetition didn’t make much difference. Column E applies hanning to Column D, and Column F applies the skip mean to Column E.
In Columns C through F, the actual number of home runs is used for the first value (for the year 1901) and for the final value (for the year 2008).
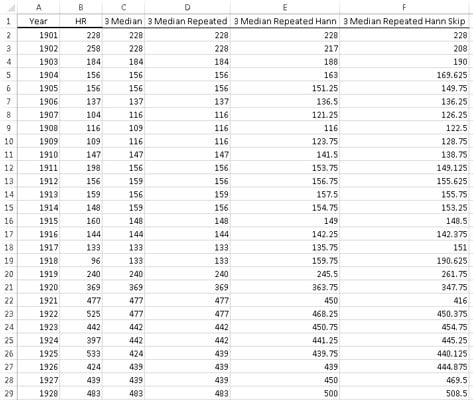
You can easily watch the effect of each successive smoothing technique on the smoothed line. The key is to right-click on the plot area and choose Select Data from the pop-up menu. Click on the name of the data series that represents the smoothed line, edit the cell range of the series to reflect the column that holds the particular smoothing technique, and click OK to close the editing dialog boxes.
And now the story begins to reveal itself. Instead of a regression line that just tells you that home runs increase as the years go by, the highs and lows stimulate thinking as to why they’re there. Here’s a highly abridged version of baseball history consistent with the twists and turns of the smoothed line.
The low flat segment from 1901 through 1920 signifies the “dead-ball era,” a time when the composition of a baseball inhibited batted balls from going far enough to become home runs.
Exploring and visualizing the data stimulates thought about what’s producing the patterns the exploration uncovers. Speculation leads to testable hypotheses, which lead to analysis.