
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) is a popular clustering algorithm used as an alternative to K-means in predictive analytics. It doesn’t require that you input the number of clusters in order to run. But in exchange, you have to tune two other parameters.
The scikit-learn implementation provides a default for the eps and min_samples parameters, but you’re generally expected to tune those. The eps parameter is the maximum distance between two data points to be considered in the same neighborhood. The min_samples parameter is the minimum amount of data points in a neighborhood to be considered a cluster.
One advantage that DBSCAN has over K-means is that DBSCAN is not restricted to a set number of clusters during initialization. The algorithm will determine a number of clusters based on the density of a region.
Keep in mind, however, that the algorithm depends on the eps and min_samples parameters to figure out what the density of each cluster should be. The thinking is that these two parameters are much easier to choose for some clustering problems.
In practice, you should test with multiple clustering algorithms.
Because the DBSCAN algorithm has a built-in concept of noise, it’s commonly used to detect outliers in the data — for example, fraudulent activity in credit cards, e-commerce, or insurance claims.
How to run the full dataset
You’ll need to load the Iris dataset into your Python session. Here’s the procedure:
Open a new Python interactive shell session.
Use a new Python session so that memory is clear and you have a clean slate to work with.
Paste the following code in the prompt and observe the output:
>>> from sklearn.datasets import load_iris >>> iris = load_iris()
After running those two statements, you should not see any messages from the interpreter. The variable iris should contain all the data from the iris.csv file.
Create an instance of DBSCAN. Type the following code into the interpreter:
>>> from sklearn.cluster import DBSCAN >>> dbscan = DBSCAN(random_state=111)
The first line of code imports the DBSCAN library into the session for you to use. The second line creates an instance of DBSCAN with default values for eps and min_samples.
Check what parameters were used by typing the following code into the interpreter:
>>> dbscan DBSCAN(eps=0.5, metric='euclidean', min_samples=5, random_state=111)
Fit the Iris data into the DBSCAN clustering algorithm by typing the following code into the interpreter:
>>> dbscan.fit(iris.data)
To check the outcome, type the following code into the interpreter:
>>> dbscan.labels_ array([ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., -1., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 1., 1., 1., 1., 1., -1., 1., 1., -1., 1., 1., 1., 1., 1., 1., 1., -1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., -1., 1., 1., 1., 1., 1., -1., 1., 1., 1., 1., -1., 1., 1., 1., 1., 1., 1., -1., -1., 1., -1., -1., 1., 1., 1., 1., 1., 1., 1., -1., -1., 1., 1., 1., -1., 1., 1., 1., 1., 1., 1., 1., 1., -1., 1., 1., -1., -1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
If you look very closely, you’ll see that DBSCAN produced three groups (–1, 0, and 1).
How to visualize the clusters
Let’s get a scatter plot of the DBSCAN output. Type the following code:
>>> from sklearn.decomposition import PCA
>>> pca = PCA(n_components=2).fit(iris.data)
>>> pca_2d = pca.transform(iris.data)
>>> for i in range(0, pca_2d.shape[0]):
>>> if dbscan.labels_[i] == 0:
>>> c1 = pl.scatter(pca_2d[i,0],pca_2d[i,1],c='r',
marker='+')
>>> elif dbscan.labels_[i] == 1:
>>> c2 = pl.scatter(pca_2d[i,0],pca_2d[i,1],c='g',
marker='o')
>>> elif dbscan.labels_[i] == -1:
>>> c3 = pl.scatter(pca_2d[i,0],pca_2d[i,1],c='b',
marker='*')
>>> pl.legend([c1, c2, c3], ['Cluster 1', 'Cluster 2',
'Noise'])
>>> pl.title('DBSCAN finds 2 clusters and noise)
>>> pl.show()
Here is the scatter plot that is the output of this code:
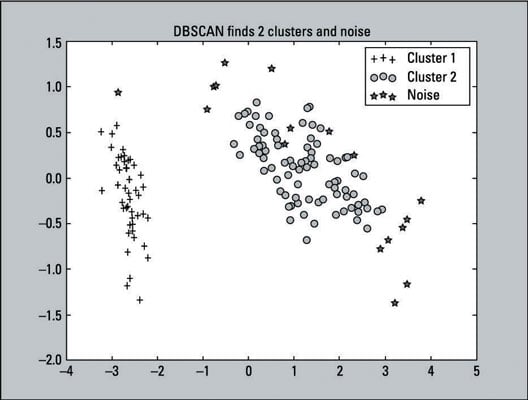
You can see that DBSCAN produced three groups. Note, however, that the figure closely resembles a two-cluster solution: It shows only 17 instances of label – 1. That’s because it’s a two-cluster solution; the third group (–1) is noise (outliers). You can increase the distance parameter (eps) from the default setting of 0.5 to 0.9, and it will become a two-cluster solution with no noise.
The distance parameter is the maximum distance an observation is to the nearest cluster. The greater the value for the distance parameter, the fewer clusters are found because clusters eventually merge into other clusters. The –1 labels are scattered around Cluster 1 and Cluster 2 in a few locations:
Near the edges of Cluster 2 (Versicolor and Virginica classes)
Near the center of Cluster 2 (Versicolor and Virginica classes)
The graph only shows a two-dimensional representation of the data. The distance can also be measured in higher dimensions.
One instance above Cluster 1 (the Setosa class)
How to evaluate the model
In this example, DBSCAN did not produce the ideal outcome with the default parameters for the Iris dataset. Its performance was pretty consistent with other clustering algorithms that end up with a two-cluster solution.
The Iris dataset does not take advantage of DBSCAN’s most powerful features — noise detection and the capability to discover clusters of arbitrary shapes. However, DBSCAN is a very popular clustering algorithm and research is still being done on improving its performance.