
MapReduce is a software framework that is ideal for big data because it enables developers to write programs that can process massive amounts of unstructured data in parallel across a distributed group of processors.
The map function for big data
The map function has been a part of many functional programming languages for years. Map has been reinvigorated as a core technology for processing lists of data elements.
Operators in functional languages do not modify the structure of the data; they create new data structures as their output. The original data itself is unmodified as well. So you can use the map function with impunity because it will not harm your precious stored data.
Another advantage to functional programming is not having to expressly manage the movement or flow of the data. This absolves the programmer from explicitly managing the data output and placement. Finally, the order of the operations on the data is not prescribed.
One way to accomplish the solution is to identify the input data and create a list:
mylist = ("all counties in the us that participated in the most recent general election")
Create the function howManyPeople using the map function. This selects only the counties with more than 50,000 people:
map howManyPeople (mylist) = [ howManyPeople "county 1"; howManyPeople "county 2"; howManyPeople "county 3"; howManyPeople "county 4"; . . . ]
Now produce a new output list of all the counties with populations greater than 50,000:
(no, county 1; yes, county 2; no, county 3; yes, county 4; ?, county nnn)
The function executes without making any changes to the original list. In addition, you can see that each element of the output list maps to a corresponding element of the input list, with a yes or no attached. If the county has met the requirement of more than 50,000 people, the map function identifies it with a yes. If not, a no is indicated.
Add the reduce function for big data
Like the map function, reduce has been a feature of functional programming languages for many years. The reduce function takes the output of a map function and “reduces” the list in whatever fashion the programmer desires.
The first step that the reduce function requires is to place a value in something called an accumulator, which holds an initial value. After storing a starting value in the accumulator, the reduce function then processes each element of the list and performs the operation you need across the list.
At the end of the list, the reduce function returns a value based on what operation you wanted to perform on the output list.
Suppose that you need to identify the counties where the majority of the votes were for the Democratic candidate. Remember that your howManyPeople map function looked at each element of the input list and created an output list of the counties with more than 50,000 people (yes) and the counties with less than 50,000 people (no).
After invoking the howManyPeople map function, you are left with the following output list:
(no, county 1; yes, county 2; no, county 3; yes, county 4; ?, county nnn)
This is now the input for your reduce function. Here is what it looks like:
countylist = (no, county 1; yes, county 2; no, county 3; yes, county 4; ?, county nnn) reduce isDemocrat (countylist)
The reduce function processes each element of the list and returns a list of all the counties with a population greater than 50,000, where the majority voted Democratic.
Putting the big data map and reduce together
Sometimes producing an output list is just enough. Likewise, sometimes performing operations on each element of a list is enough. Most often, you want to look through large amounts of input data, select certain elements from the data, and then compute something of value from the relevant pieces of data.
You don’t want to change that input list so you can use it in different ways with new assumptions and new data.
Software developers design applications based on algorithms. An algorithm is nothing more than a series of steps that need to occur in service to an overall goal. It might look a little like this:
Start with a large number or data or records.
Iterate over the data.
Use the map function to extract something of interest and create an output list.
Organize the output list to optimize for further processing.
Use the reduce function to compute a set of results.
Produce the final output.
Programmers can implement all kinds of applications using this approach, but the examples to this point have been very simple, so the real value of MapReduce may not be apparent. What happens when you have extremely large input data? Can you use the same algorithm on terabytes of data? The good news is yes.
All of the operations seem independent. That’s because they are. The real power of MapReduce is the capability to divide and conquer. Take a very large problem and break it into smaller, more manageable chunks, operate on each chunk independently, and then pull it all together at the end. Furthermore, the map function is commutative — in other words, the order that a function is executed doesn’t matter.
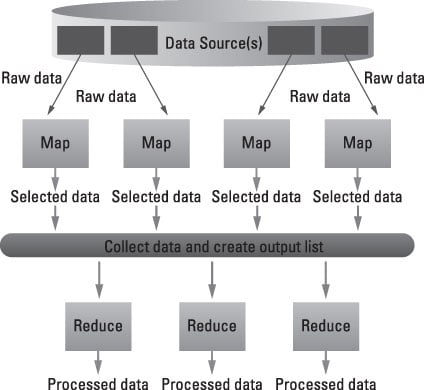
So MapReduce can perform its work on different machines in a network. It can also draw from multiple data sources, internal or external. MapReduce keeps track of its work by creating a unique key to ensure that all the processing is related to solving the same problem. This key is also used to pull all the output together at the end of all the distributed tasks.