
It is important to lay a strong architectural foundation if you want to be successful with big data. In addition to supporting the functional requirements, it is important to support the required performance. Your needs will depend on the nature of the analysis you are supporting. You will need the right amount of computational power and speed.
Your architecture also has to have the right amount of redundancy so that you are protected from unanticipated latency and downtime.
Start out by asking yourself the following questions:
How much data will your organization need to manage today and in the future?
How often will your organization need to manage data in real time or near real time?
How much risk can your organization afford? Is your industry subject to strict security, compliance, and governance requirements?
How important is speed to your need to manage data?
How certain or precise does the data need to be?
Interfaces and feeds for big data
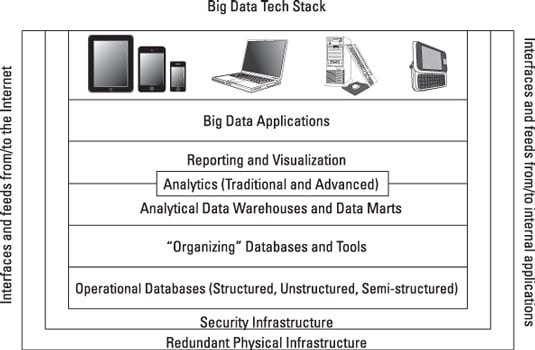
To understand how big data works in the real world, it is important to start by understanding the necessity of interfaces and feeds. In fact, what makes big data big is the fact that it relies on picking up lots of data from lots of sources.
Therefore, open application programming interfaces (APIs) will be core to any big data architecture. In addition, keep in mind that interfaces exist at every level and between every layer of the stack. Without integration services, big data can’t happen.
Redundant big data physical infrastructure
The supporting physical infrastructure is fundamental to the operation and scalability of a big data architecture. In fact, without the availability of robust physical infrastructures, big data would probably not have emerged as such an important trend. To support an unanticipated or unpredictable volume of data, a physical infrastructure for big data has to be different than that for traditional data.
The physical infrastructure is based on a distributed computing model. This means that data may be physically stored in many different locations and can be linked together through networks, the use of a distributed file system, and various big data analytic tools and applications.
Redundancy is important because you are dealing with so much data from so many different sources. Redundancy comes in many forms. If your company has created a private cloud, you will want to have redundancy built within the private environment so that it can scale out to support changing workloads.
If your company wants to contain internal IT growth, it may use external cloud services to augment its internal resources. In some cases, this redundancy may come in the form of a Software as a Service (SaaS) offering that allows companies to do sophisticated data analysis as a service. The SaaS approach offers lower costs, quicker startup, and seamless evolution of the underlying technology.
Big Data security infrastructure
The more important big data analysis becomes to companies, the more important it will be to secure that data. For example, if you are a healthcare company, you will probably want to use big data applications to determine changes in demographics or shifts in patient needs. This data about your constituents needs to be protected both to meet compliance requirements and to protect the patients’ privacy.
You will need to take into account who is allowed to see the data and under what circumstances they are allowed to do so. You will need to be able to verify the identity of users as well as protect the identity of patients.
Operational big data sources
It is important to understand that you have to incorporate all the data sources that will give you a complete picture of your business and see how the data impacts the way you operate your business. As the world changes, it is important to understand that operational data now has to encompass a broader set of data sources, including unstructured sources such as social media data in all its forms.
You find new emerging approaches to data management in the big data world, including document, graph, columnar, and geospatial database architectures. Collectively, these are referred to as NoSQL, or not only SQL, databases. In essence, you need to map the data architectures to the types of transactions.
Doing so will help to ensure the right data is available when you need it. You also need data architectures that support complex unstructured content. You need to include both relational databases and nonrelational databases in your approach to harnessing big data. It is also necessary to include unstructured data sources, such as content management systems, so that you can get closer to that 360-degree business view.
All these operational data sources have several characteristics in common:
They represent systems of record that keep track of the critical data required for real-time, day-to-day operation of the business.
They are continually updated based on transactions happening within business units and from the web.
For these sources to provide an accurate representation of the business, they must blend structured and unstructured data.
These systems also must be able to scale to support thousands of users on a consistent basis. These might include transactional e-commerce systems, customer relationship management systems, or call center applications.