
Some data sets have a distinct shape. Here are three shapes that stand out:
-
Symmetric. A histogram is symmetric if you cut it down the middle and the left-hand and right-hand sides resemble mirror images of each other:
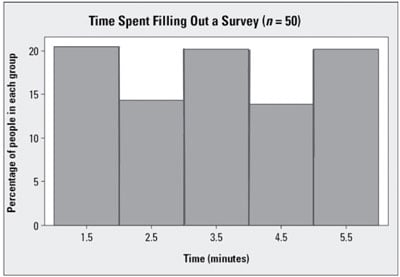 The above graph shows a symmetric data set; it represents the amount of time each of 50 survey participants took to fill out a certain survey. You see that the histogram is close to symmetric.
The above graph shows a symmetric data set; it represents the amount of time each of 50 survey participants took to fill out a certain survey. You see that the histogram is close to symmetric. -
Skewed right. A skewed right histogram looks like a lopsided mound, with a tail going off to the right:
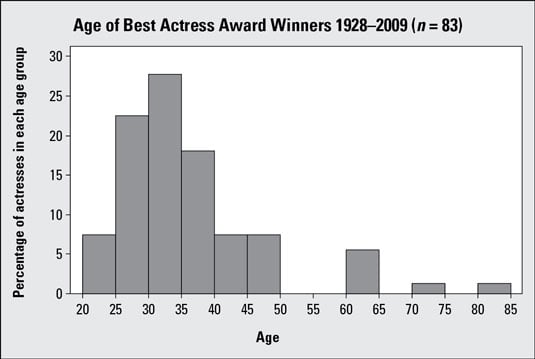 This graph, which shows the ages of the Best Actress Academy Award winners, is skewed right. You see on the right side there are a few actresses whose ages are older than the rest. Most of the actresses were between 20 and 50 years of age when they won. A few actresses were between 60–65 years of age when they won their Oscars, and a handful were 70 years or older. The last three bars are what make the data have a shape that is skewed right.
This graph, which shows the ages of the Best Actress Academy Award winners, is skewed right. You see on the right side there are a few actresses whose ages are older than the rest. Most of the actresses were between 20 and 50 years of age when they won. A few actresses were between 60–65 years of age when they won their Oscars, and a handful were 70 years or older. The last three bars are what make the data have a shape that is skewed right. -
Skewed left. If a histogram is skewed left, it looks like a lopsided mound with a tail going off to the left:
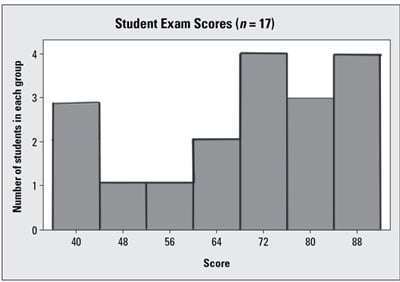 This graph shows a histogram of 17 exam scores. The shape is skewed left; you see a few students who scored lower than everyone else.
This graph shows a histogram of 17 exam scores. The shape is skewed left; you see a few students who scored lower than everyone else.
-
Don't expect symmetric data to have an exact and perfect shape. Data hardly ever fall into perfect patterns, so you have to decide whether the data shape is close enough to be called symmetric.
If the differences aren't significant enough, you can classify it as symmetric or roughly symmetric. Otherwise, you classify the data as non-symmetric.
-
Don't assume that data are skewed if the shape is non-symmetric. Data sets come in all shapes and sizes, and many of them don't have a distinct shape at all. Skewness is mentioned here because it's one of the more common non-symmetric shapes, and it's one of the shapes included in a standard introductory statistics course.
If a data set does turn out to be skewed (or close to it), make sure to denote the direction of the skewness (left or right).