
After you build your first classification predictive model for analysis of the data, creating more models like it is a really straightforward task in scikit. The only real difference from one model to the next is that you may have to tune the parameters from algorithm to algorithm.
How to load your data
This code listing will load the iris dataset into your session:
>>> from sklearn.datasets import load_iris >>> iris = load_iris()
How to create an instance of the classifier
The following two lines of code create an instance of the classifier. The first line imports the logistic regression library. The second line creates an instance of the logistic regression algorithm.
>>> from sklearn import linear_model >>> logClassifier = linear_model.LogisticRegression(C=1, random_state=111)
Notice the parameter (regularization parameter) in the constructor. The regularization parameter is used to prevent overfitting. The parameter isn’t strictly necessary (the constructor will work fine without it because it will default to C=1). Creating a logistic regression classifier using C=150 creates a better plot of the decision surface. You can see both plots below.
How to run the training data
You’ll need to split the dataset into training and test sets before you can create an instance of the logistic regression classifier. The following code will accomplish that task:
>>> from sklearn import cross_validation >>> X_train, X_test, y_train, y_test = cross_validation.train_test_split(iris.data, iris.target, test_size=0.10, random_state=111) >>> logClassifier.fit(X_train, y_train)
Line 1 imports the library that allows you to split the dataset into two parts.
Line 2 calls the function from the library that splits the dataset into two parts and assigns the now-divided datasets to two pairs of variables.
Line 3 takes the instance of the logistic regression classifier you just created and calls the fit method to train the model with the training dataset.
How to visualize the classifier
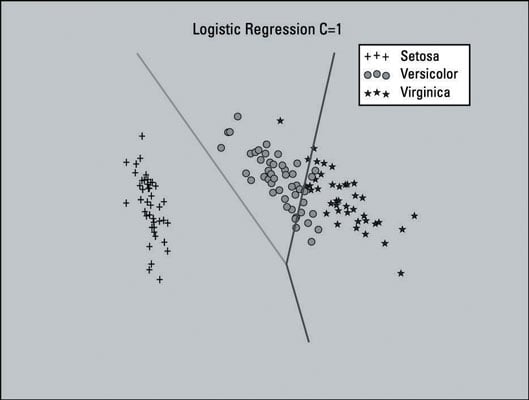
Looking at the decision surface area on the plot, it looks like some tuning has to be done. If you look near the middle of the plot, you can see that many of the data points belonging to the middle area (Versicolor) are lying in the area to the right side (Virginica).
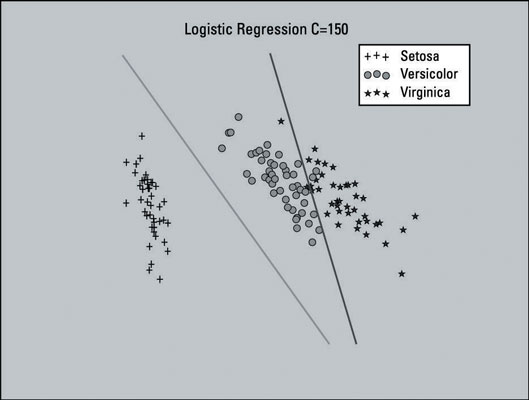
This image shows the decision surface with a C value of 150. It visually looks better, so choosing to use this setting for your logistic regression model seems appropriate.
How to run the test data
In the following code, the first line feeds the test dataset to the model and the third line displays the output:
>>> predicted = logClassifier.predict(X_test) >>> predictedarray([0, 0, 2, 2, 1, 0, 0, 2, 2, 1, 2, 0, 2, 2, 2])
How to evaluate the model
You can cross-reference the output from the prediction against the y_test array. As a result, you can see that it predicted all the test data points correctly. Here’s the code:
>>> from sklearn import metrics >>> predictedarray([0, 0, 2, 2, 1, 0, 0, 2, 2, 1, 2, 0, 2, 2, 2]) >>> y_testarray([0, 0, 2, 2, 1, 0, 0, 2, 2, 1, 2, 0, 2, 2, 2]) >>> metrics.accuracy_score(y_test, predicted)1.0 # 1.0 is 100 percent accuracy >>> predicted == y_testarray([ True, True, True, True, True, True, True, True, True, True, True, True, True, True, True], dtype=bool)
So how does the logistic regression model with parameter C=150 compare to that? Well, you can’t beat 100 percent. Here is the code to create and evaluate the logistic classifier with C=150:
>>> logClassifier_2 = linear_model.LogisticRegression( C=150, random_state=111) >>> logClassifier_2.fit(X_train, y_train) >>> predicted = logClassifier_2.predict(X_test) >>> metrics.accuracy_score(y_test, predicted)0.93333333333333335 >>> metrics.confusion_matrix(y_test, predicted)array([[5, 0, 0], [0, 2, 0], [0, 1, 7]])
We expected better, but it was actually worse. There was one error in the predictions. The result is the same as that of the Support Vector Machine (SVM) model.
Here is the full listing of the code to create and evaluate a logistic regression classification model with the default parameters:
>>> from sklearn.datasets import load_iris >>> from sklearn import linear_model >>> from sklearn import cross_validation >>> from sklearn import metrics >>> iris = load_iris() >>> X_train, X_test, y_train, y_test = cross_validation.train_test_split(iris.data, iris.target, test_size=0.10, random_state=111) >>> logClassifier = linear_model.LogisticRegression(, random_state=111) >>> logClassifier.fit(X_train, y_train) >>> predicted = logClassifier.predict(X_test) >>> predictedarray([0, 0, 2, 2, 1, 0, 0, 2, 2, 1, 2, 0, 2, 2, 2]) >>> y_testarray([0, 0, 2, 2, 1, 0, 0, 2, 2, 1, 2, 0, 2, 2, 2]) >>> metrics.accuracy_score(y_test, predicted)1.0 # 1.0 is 100 percent accuracy >>> predicted == y_testarray([ True, True, True, True, True, True, True, True, True, True, True, True, True, True, True], dtype=bool)