
The Hadoop Distributed File System is a versatile, resilient, clustered approach to managing files in a big data environment. HDFS is not the final destination for files. Rather, it is a data service that offers a unique set of capabilities needed when data volumes and velocity are high. Because the data is written once and then read many times thereafter, rather than the constant read-writes of other file systems, HDFS is an excellent choice for supporting big data analysis.
Big data NameNodes
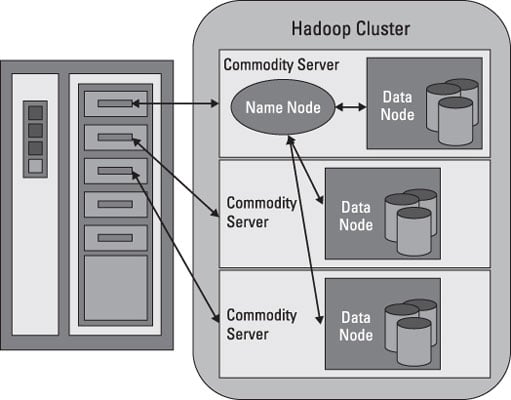
HDFS works by breaking large files into smaller pieces called blocks. The blocks are stored on data nodes, and it is the responsibility of the NameNode to know what blocks on which data nodes make up the complete file. The NameNode also acts as a “traffic cop,” managing all access to the files.
The complete collection of all the files in the cluster is sometimes referred to as the file system namespace. It is the NameNode’s job to manage this namespace.
Even though a strong relationship exists between the NameNode and the data nodes, they operate in a “loosely coupled” fashion. This allows the cluster elements to behave dynamically, adding servers as the demand increases. In a typical configuration, you find one NameNode and possibly a data node running on one physical server in the rack. Other servers run data nodes only.
The data nodes communicate among themselves so that they can cooperate during normal file system operations. This is necessary because blocks for one file are likely to be stored on multiple data nodes. Since the NameNode is so critical for correct operation of the cluster, it can and should be replicated to guard against a single point failure.
Big data nodes
Data nodes are not smart, but they are resilient. Within the HDFS cluster, data blocks are replicated across multiple data nodes and access is managed by the NameNode. The replication mechanism is designed for optimal efficiency when all the nodes of the cluster are collected into a rack. In fact, the NameNode uses a “rack ID” to keep track of the data nodes in the cluster.
Data nodes also provide “heartbeat” messages to detect and ensure connectivity between the NameNode and the data nodes. When a heartbeat is no longer present, the NameNode unmaps the data node from the cluster and keeps on operating as though nothing happened. When the heartbeat returns, it is added to the cluster transparently with respect to the user or application.
Data integrity is a key feature. HDFS supports a number of capabilities designed to provide data integrity. As you might expect, when files are broken into blocks and then distributed across different servers in the cluster, any variation in the operation of any element could affect data integrity. HDFS uses transaction logs and checksum validation to ensure integrity across the cluster.
Transaction logs keep track of every operation and are effective in auditing or rebuilding of the file system should something untoward occur.
Checksum validations are used to guarantee the contents of files in HDFS. When a client requests a file, it can verify the contents by examining its checksum. If the checksum matches, the file operation can continue. If not, an error is reported. Checksum files are hidden to help avoid tampering.
Data nodes use local disks in the commodity server for persistence. All the data blocks are stored locally, primarily for performance reasons. Data blocks are replicated across several data nodes, so the failure of one server may not necessarily corrupt a file. The degree of replication, the number of data nodes, and the HDFS namespace are established when the cluster is implemented.
HDFS for big data
HDFS addresses big data challenges by breaking files into a related collection of smaller blocks. These blocks are distributed among the data nodes in the HDFS cluster and are managed by the NameNode. Block sizes are configurable and are usually 128 megabytes (MB) or 256MB, meaning that a 1GB file consumes eight 128MB blocks for its basic storage needs.
HDFS is resilient, so these blocks are replicated throughout the cluster in case of a server failure. How does HDFS keep track of all these pieces? The short answer is file system metadata.
Metadata is defined as “data about data.” Think of HDFS metadata as a template for providing a detailed description of the following:
When the file was created, accessed, modified, deleted, and so on
Where the blocks of the file are stored in the cluster
Who has the rights to view or modify the file
How many files are stored on the cluster
How many data nodes exist in the cluster
The location of the transaction log for the cluster
HDFS metadata is stored in the NameNode, and while the cluster is operating, all the metadata is loaded into the physical memory of the NameNode server. As you might expect, the larger the cluster, the larger the metadata footprint.
What exactly does a block server do? Check out the following list:
Stores the data blocks in the local file system of the server. HDFS is available on many different operating systems and behaves the same whether on Windows, Mac OS, or Linux.
Stores the metadata of a block in the local file system based on the metadata template in the NameNode.
Performs periodic validations of file checksums.
Sends regular reports to the NameNode about what blocks are available for file operations.
Provides metadata and data to clients on demand. HDFS supports direct access to the data nodes from client application programs.
Forwards data to other data nodes based on a “pipelining” model.
Block placement on the data nodes is critical to data replication and support for data pipelining. HDFS keeps one replica of every block locally. HDFS is serious about data replication and resiliency.